14 Diversity
14.1 Background
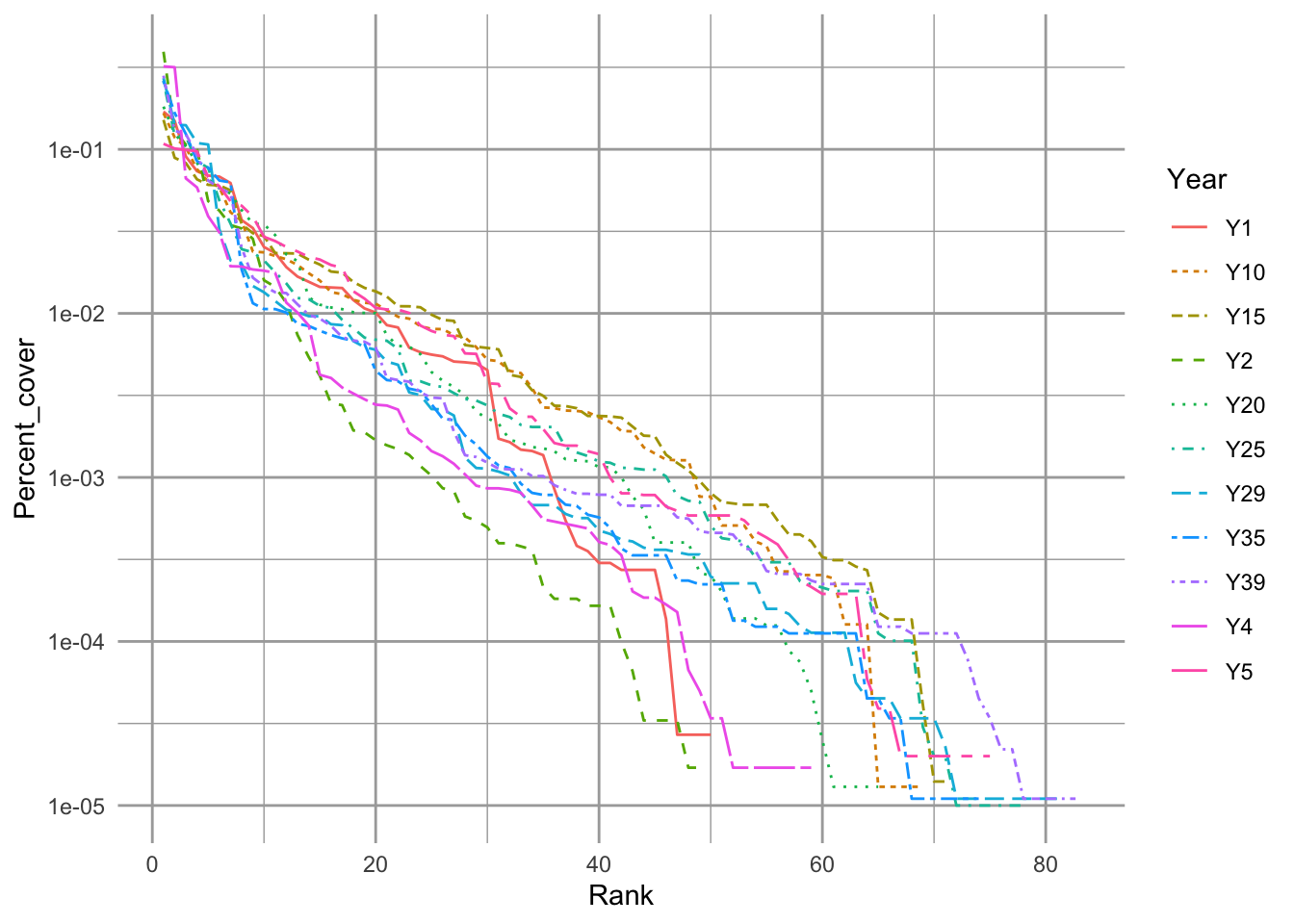
Figure 14.1: Empirical rank–abundance distributions of successional plant communities (old-fields) within the temperate deciduous forest biome of North America. ‘Year’ indicates the time since abandonment from agriculture. Data from the Buell-Small succession study (http://www.ecostudies.org/bss/).
It seems easy, or at least tractable, to compare the abundance of a single species in two samples. In this chapter, we introduce conceptsthat ecologists use to compare entire communities in two samples. We focus on two quantities: species composition, and diversity. We also discuss several issues related to this, including species–abundance distributions, ecological neutral theory, diversity partitioning, and species–area relations. Several packages in R include functions for dealing specifically with these topics.
Please see the “Environmetrics” link within the “Task Views” link at any CRAN website for downloading R packages. Perhaps the most comprehensive (including both diversity and composition) is the vegan package, but many others include important features as well.
14.2 Species Composition
Differences in species composition among communities is a form of \(\beta\)–diversity. Understanding the patterns and processes by which communities change or differs in space and time is perhaps the principal goal of community ecology. Beta-diversity is the term we give to these differences. Understanding precisely what we mean it is essential for correctly addressing our questions, and Anderson et al. (2011) have provided us with an excellent roadmap to help. All of the questions and their answers rely on a proper understanding of multivariate distance. And that requires us to start with species composition.
Species composition is merely the set of species in a site or a sample. Typically this includes some measure of abundance at each site, but it may also simply be a list of species at each site, where “abundance” is either presence or absence.
Imagine we have four sites (A–D) from which we collect density data on two species, Salix whompii and Fraxinus virga. We can enter hypothetical data of the following abundances.
dens <- data.frame(Salwho=c(1,0,2,3), Fravir=c(21,8,13,5))
row.names(dens) <- LETTERS[1:4]
dens## Salwho Fravir
## A 1 21
## B 0 8
## C 2 13
## D 3 5Next, we plot the abundances of both species; the plotted points then are the sites (Fig. 14.2).
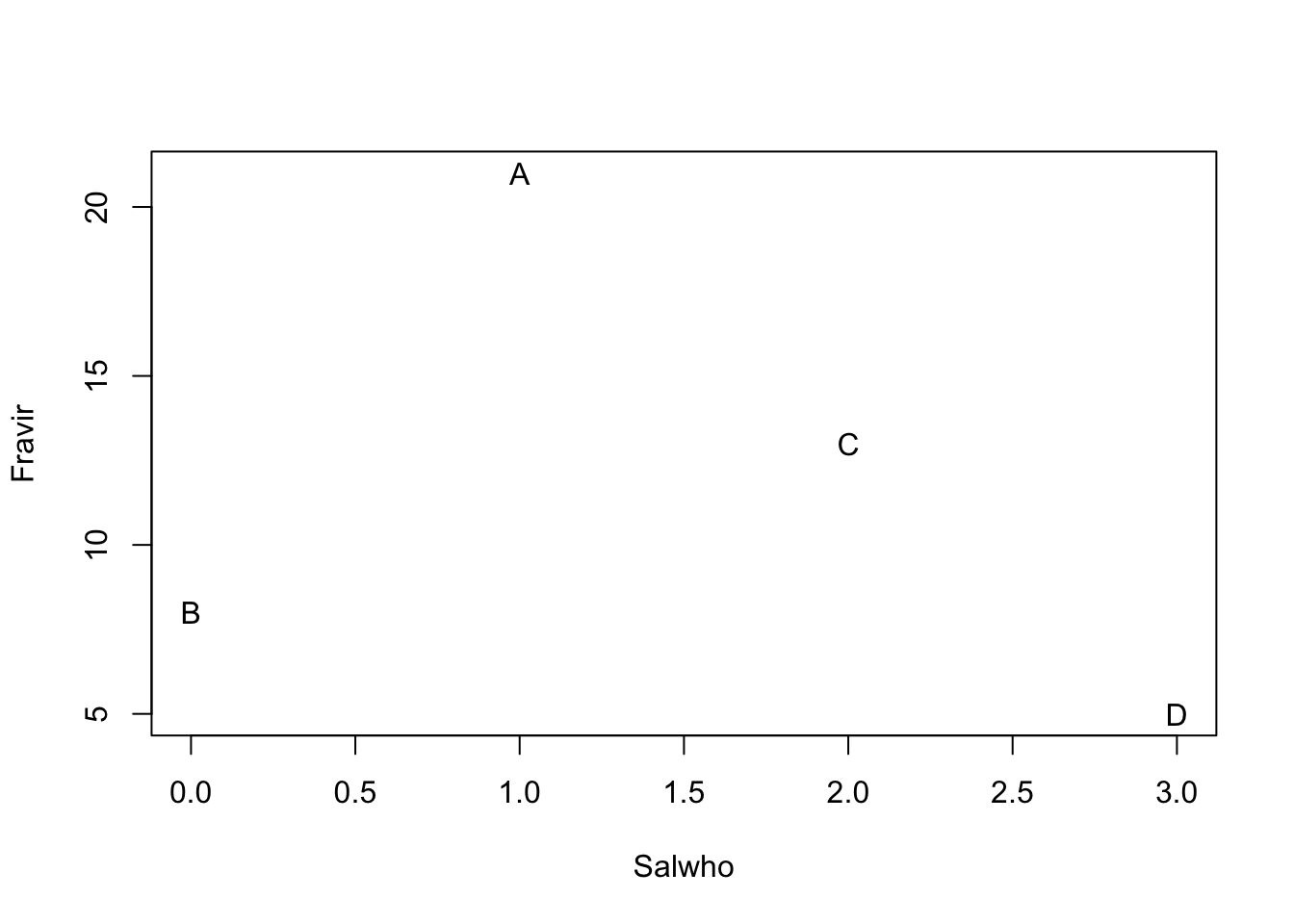
Figure 14.2: Hypothetical species composition for four sites (A–D)
In Fig. 14.2, we see that the species composition in site A is most different from the composition of site D. That is, the distance between site A and D is greater than between any other sites. The next question, then, is how far apart are any two sites? Clearly, this depends on the scale of the measurement (e.g., the values on the axes), and also on how we measure distance through multivariate space.
14.2.1 Measures of abundance
Above we pretended that the abundances were absolute densities (i.e., 1 = one stem per sample). We could of course represent all the abundances differently. For instance, we could calculate relative density, where each species in a sample is represented by the proportion of the sample comprised of that species. For site A, we divide each species by the sum of all species.
dens[1,]/sum(dens[1,])## Salwho Fravir
## A 0.04545455 0.9545455We see that Salix makes up about 5% of the sample for Site A, and Fraxinus makes up about 95% of the sample. Once we calculate relative densities for each species at each site, this eliminates differences in total density at each site because all sites then total to 1.
We could also calculate relative measures for any type of data, such as biomass or percent cover.
In most instances, relative density refers to the density of a species relative to the other species in a sample (above), but it can also be density in a sample relative to other samples. We would thus make each species total equal 1, and then its abundance at each site reflects the proportion of a species total abundance comprised by that site. For instance, we can make all Salix densities relative to each other.
dens[,1]/sum(dens[,1])## [1] 0.1666667 0.0000000 0.3333333 0.5000000Here we see that sites A and B both have about 14% of all Salix stems, and site D has 43%.
Whether our measures of abundance are absolute or relative, we would like to know how different samples (or sites) are from each other. Perhaps the simplest way to describe the difference among the sites is to calculate the distances or dissimilarities between each pair of sites.
14.2.2 Dissimilarities and Distances
When we have data on just the presence and absence of species, we can calculate a difference between sites using the Jaccard index of similarity,
\[J_{AB} = \frac{A \cap B}{A \cup B}\] where the numerator is the number of species in the set of shared species (present at both sites) and the denominator is the number of species in the set present at either site. Among our sites, the Jaccard index between site B and site A is \[J_{BA} = \frac{1}{2}\] and this is the same between site B and C and D as well. Jaccard dissimilarity is \(1 - J\). This would be \(0.5\) for site B and any other site, and zero for the other pairs.
There is a quantitative version of this, which is \[J_{AB} = \frac{\sum_{i=1}^S \min (x_i)}{\sum_{i=1}^S \max (x_i)}\] where \(x_i\) is the abundance of \(i\). For sites A and B, this would be,
\[J_{AB} = \frac{0+8}{1+21}=4/11 = 0.\overline{36}\] and so dissimilarity would again be \(1-J_{AB}\).
Euclidean distance is another important way to measure differences between sites. With two species, we have two dimensional space, which is Fig. 14.2. The Euclidean distance between two sites is merely the length of the vector connecting those sites. We calculate this as \(\sqrt{x^2+y^2}\), where \(x\) and \(y\) are the \((x,y)\) distances between a pair of sites. The \(x\) distance between sites B and C is the difference in Salix abundance between the two sites,
x <- dens[2,1] - dens[3,1]where dens is the data frame with sites in rows, and species in different columns. The \(y\) distance between sites B and C is difference in Fraxinus abundance between the two sites.
y <- dens[2,2] - dens[3,2]The Euclidean distance between these is therefore
sqrt(x^2 + y^2)## [1] 5.385165We calculate all pairwise Euclidean distances between sites A–D based on 2 species using built-in functions in R.
(alldists <- dist(dens))## A B C
## B 13.038405
## C 8.062258 5.385165
## D 16.124515 4.242641 8.062258We can generalize this to include any number of species, but it becomes increasingly harder to visualize. We can add a third species, Mandragora officinarum, and recalculate pairwise distances between all sites, but now with three species.
## A B C
## B 15.297059
## C 9.000000 6.708204
## D 17.204651 4.690416 8.306624We can plot species abundances as we did above, and pairs(dens) would give us all the pairwise plots given three species. However, what we really want for species is a 3-D plot. Here we load another package and create a 3-D scatterplot.
library(scatterplot3d)
sc1 <- scatterplot3d(dens, type='h', pch="",
xlim=c(0,5), ylim=c(0, 25), zlim=c(0,15))
text(sc1$xyz.convert(dens), labels=rownames(dens))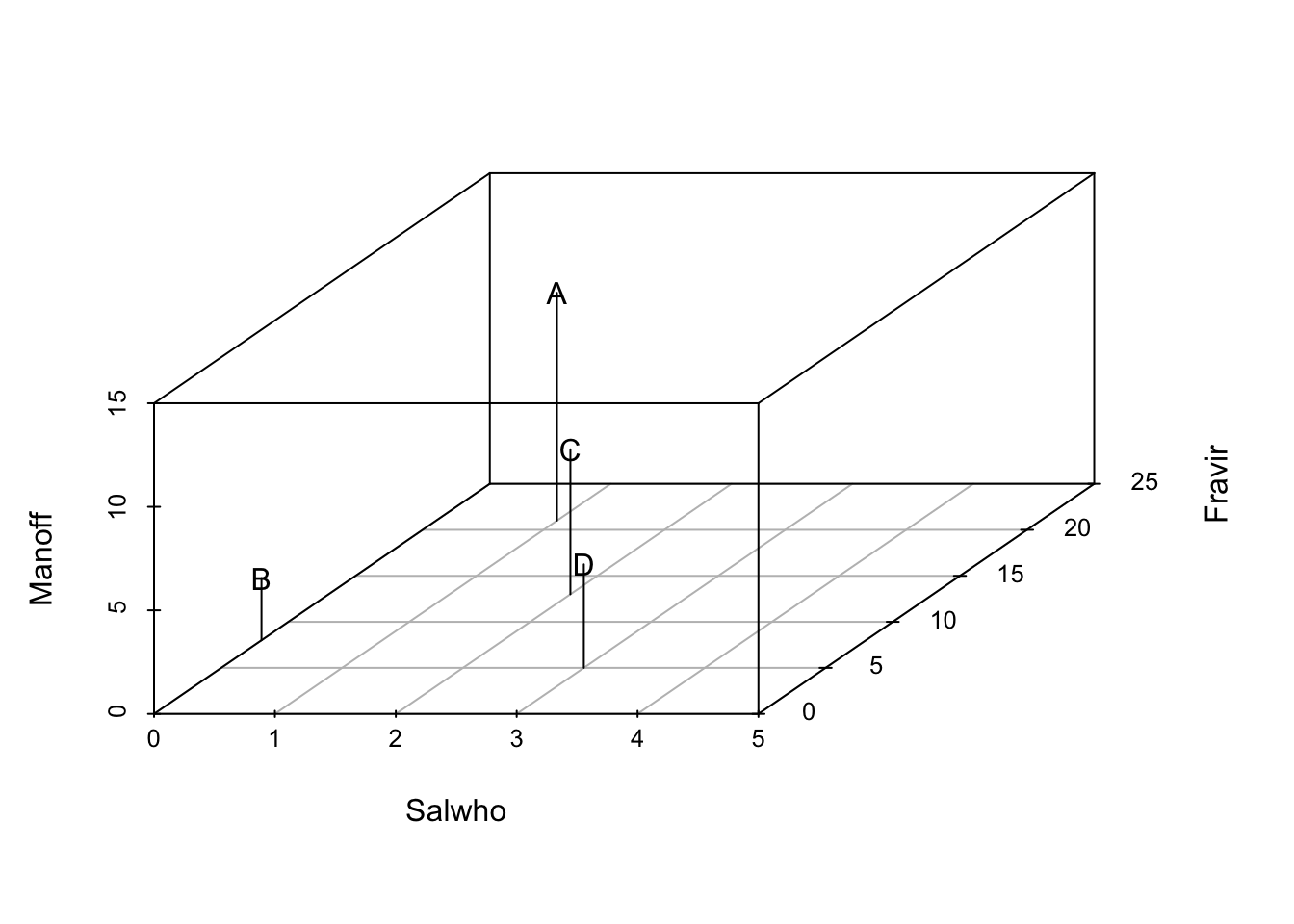 In three dimensions, Euclidean distances are calculated the same basic way, but we add a third species, and the calculation becomes \(\sqrt{x^2 + y^2 +z^2}\). Note that we take the square root (as opposed to the cube root) because we originally squared each distance. We can generalize this for two sites for \(S\) species as
\[D_E = \sqrt{\sum_{i=1}^S\left( x_{ai} - x_{bi}\right)^2}\]
In three dimensions, Euclidean distances are calculated the same basic way, but we add a third species, and the calculation becomes \(\sqrt{x^2 + y^2 +z^2}\). Note that we take the square root (as opposed to the cube root) because we originally squared each distance. We can generalize this for two sites for \(S\) species as
\[D_E = \sqrt{\sum_{i=1}^S\left( x_{ai} - x_{bi}\right)^2}\]
Of course, it is difficult (impossible?) to visualize arrangements of sites with more than three axes (i.e., \(>3\) species), but we can always calculate the distances between pairs of sites, regardless of how many species we have.
There are many ways, in addition to Euclidean distances, to calculate differences. Among the most commonly used in ecology is Bray–Curtis dissimilarity, which goes by other names, including Sørenson dissimilarity \[D_{BC} = \frac{\sum_{i=1}^S\left| x_{ai} - x_{bi}\right|}{\sum_{i=1}^S (x_{ai} + x_{bi})}\] where \(S\) is the number of species in all samples. Bray–Curtis dissimilarity is merely the total difference in species abundances between two sites, divided by the total abundances at each site. Bray–Curtis dissimilarity (and a couple others) tends to result in more intuitively pleasing distances in which both common and rare species have relatively similar weights, whereas Euclidean distance depends more strongly on the most abundant species. This happens because Euclidean distances are based on squared differences, whereas Bray–Curtis uses absolute differences. Squaring always amplifies the importance of larger values. Fig. 14.3 compares graphs based on Euclidean and Bray–Curtis differences of the same raw data.
[Add note on distance vs. dissimilarity, and the triangle inequality]
14.2.3 Displaying multidimensional distances
A simple way to display distances for three or more species is to create a plot in two dimensions that attempts to arrange all sites so that they are approximately the correct distances apart. In general this is impossible to achieve precisely, but distances can be approximately correct. One technique that tries to create an optimal (albiet approximate) arrangement is non-metric multidimensional scaling. Here we add a fourth species (Aconitum lycoctonum) to our data set before plotting the distances.
dens$Acolyc <- c(16, 0, 9,4)The non-metric multidimensional scaling function is in the package. It calculates distances for us using the original data. Here we display Euclidean distances among sites (Fig. 14.3).
# ignore warnings for these toy examples
mdsE <- metaMDS(dens, distance="euc", autotransform=FALSE, trace=0)
plot(mdsE, display="sites", type="text")
mdsB <- metaMDS(dens, distance="bray", autotransform=FALSE, trace=0)
plot(mdsB, display="sites", type="text")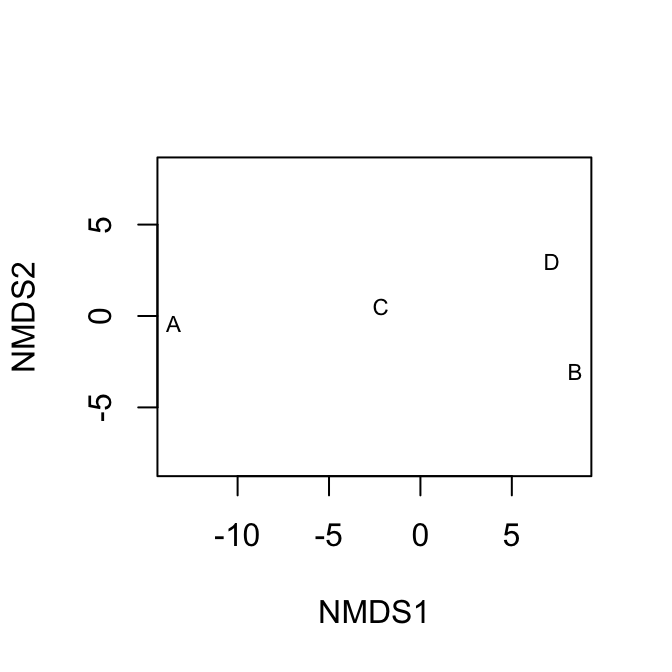
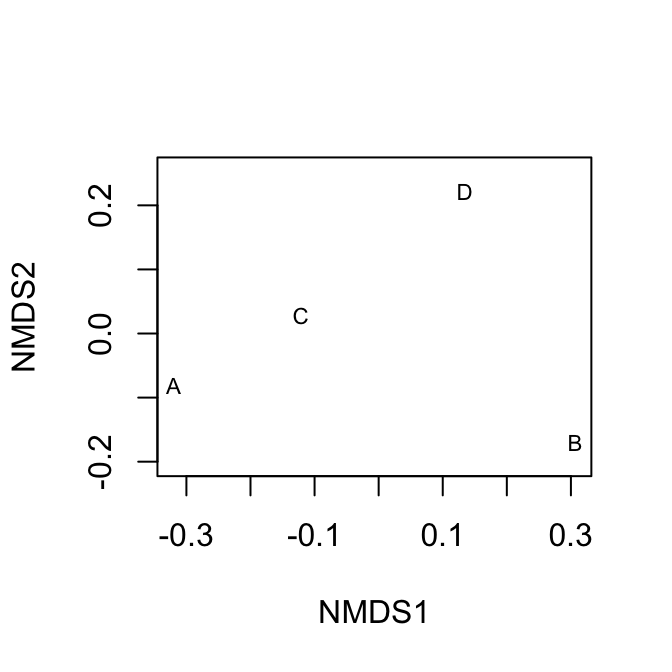
Figure 14.3: Nonmetric multidimensional (NMDS) plots showing approximate distances between sites. These two figures display the same raw data, but Euclidean distances tend to emphasize differences due to the more abundant species, whereas Bray-Curtis does not. Because NMDS provides iterative optimizations, it will find slightly different arrangements each time you run it.
14.3 Diversity
To my mind, there is no more urgent or interesting goal in ecology and evolutionary biology than understanding the determinants of biodiversity. Biodiversity is many things to many people, but we typically think of it as a measure of the variety of biological life present, perhaps taking into account the relative abundances. For ecologists, we most often think of species diversity as some quantitative measure of the variety or number of different species. This has direct analogues to the genetic diversity within a population (Crow and Kimura 1970; Vellend 2017), and the connections between species and genetic diversity include both shared patterns and shared mechanisms. Here we confine ourselves entirely to a discussion of species diversity, the variety of different species present.
14.4 Species diversity
Species diversity represents the variety of species in a community or a sample of a community. Fig. 14.1 shows us at a glance the distributions of species abundances, and thus the diversities, of a plant community at different points in time as it undergoes secondary succession. In the figure we see the number of different species that are present (x-axis), and the relative abundances (y-axis). This image gives us an intuition about the variety of species we might encounter. It shows us whether we might expect to encounter many different species, or whether the community might be dominated by one or just a few species. The sense is what we try to capture in a single number that we call a “diversity index”.
Species diversity is closely allied with mechanisms of coexistence. When two areas differ in their diversity, we are likely to ask why this is so. The number and variety of species present will depend on how many species are available to colonize an area, and also on the mechanisms that allow them to coexist locally. Robert H. MacArthur and Wilson (1963) envisioned this in terms of ecology, where the number of species in an area is s function of rates of immigration and local extinction, \[S = \Delta I - \Delta E\] where mechanisms of coexistence govern \(\Delta E\). This equation is the basis for the theory of island biogeography (Robert H. MacArthur and Wilson 1963; R. H. MacArthur and Wilson 1967). More on that later.
There are many diversity indices that we could calculate; here, we will calculate four different measures: species richness, Shannon-Weiner diversity, Simpson’s diversity, and Simpson’s inverse diversity. These sometimes are referred to by slightly different names, so it is important to figure out exactly what someone has done.
Let’s start by creating two samples of two different communities.
comm <- rep(c("X","Y"), each=4)
spp <- letters[c(1:4, 1:4)]
abun <- c(10,3,1,0, 4,1,6,3)
rank <- c(1,2,3,4, 2,4,1,3)
df <- data.frame(comm=comm, spp=spp, n=abun, rank=rank)
ggplot(df, aes(rank, n, colour=comm, linetype=comm)) +
geom_line() + lims(y=c(1,10)) 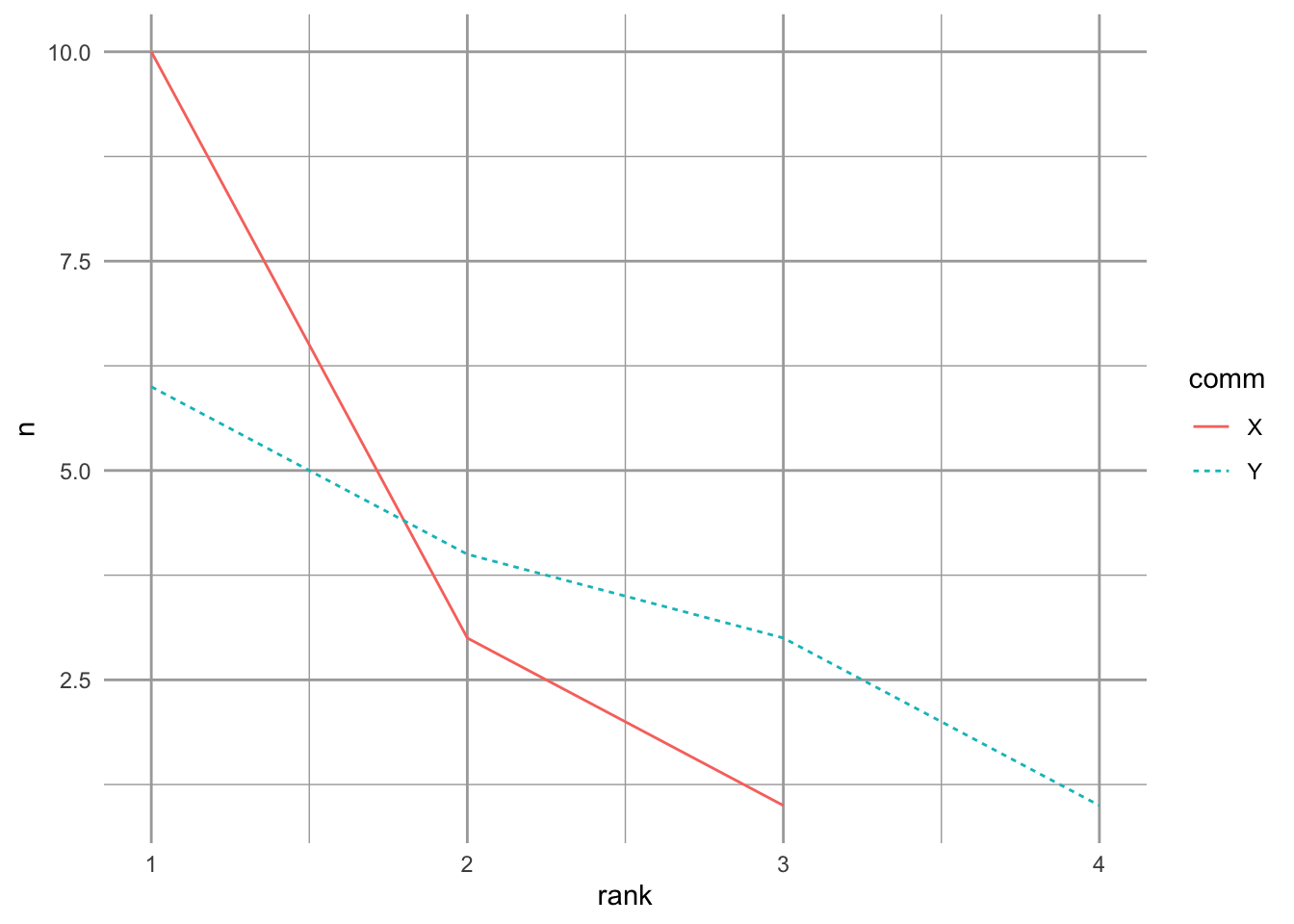
Figure 14.4: Two toy communities.
These two samples have different numbers of species, and different distributions. Community Y has a more even distribution of species abundances, whereas community X is dominated by a single species. Now we’ll calculate our different measures of species diversity.
Species richness is simply the number of different species in the sample. It is the value of the x-axis in the above figure. To calculate that from these data, we will determine the lengths of the vectors of nonzero abundances.
## X Y
## 3 4Species richness increases as the number of individuals in the sample increases. Therefore, care should be taken in comparing the richness of two different samples to make sure that they are sufficiently comparable.
When most ecologists use the term ‘species diversity’ they are not referring to species richness, but rather some index that incorporates relative abundance as well. One of the most common of these is Shannon-Weiner diversity or the Shannon index. This quantity has its roots in information theory and entropy. It measures the disorder in a data set. For instance, if nearly all of the individuals are a single species, then the data are highly predictable and ordered. In contrast, if there are many individuals of many different species, then it would be very difficult to describe in a simple way, and difficult to predict what a sample would look like–disorder, or entropy, would be high. The Shannon index is \[H=-\sum_{i-1}^Sp_i\log p_i\] where \(p_i\) is the proportion of individuals belonging to species \(i\).
# a function that starts with abundances and calculates H
shannon <- function(n) {
n <- n[n>0] # remove zero values
p <- n/sum(n)
-1 * sum( p*log(p) )
}
tapply(X=df$n, INDEX=df$comm,
FUN = shannon)## X Y
## 0.7589368 1.2396594These numbers provide relative estimates of “variety”. They increase with increasing species richness and with increasing evenness of abundances. While there is no hypothetical upper limit, it ranges the minimum is zero for a single species, and five or six for hyper-diverse communities.
Simpson diversity indices are based on the Simpson dominance index. The dominance index is the probability that two randomly selected individuals belong to the same species, \[D = \sum_{i=1}^S p_i^2\] which varies between 1 for a single species and declines toward zero with increasing numbers of species and increasing number of species. If we were describing alleles, instead of trees, this value is the inbreeding coefficient, of genetic homozygosity Nei (1987). It is also referred to as the Gini coefficient, and was formulated to measure income inequality. This value is used in two ways in aid calculation of diversity. One Simpson’s diversity index is the arithmetic complement, \[S_c = 1-D\], which is the probability that two randomly selected individuals belong to different species. It is also the initial slope of the expected individuals (\(x\)) vs. species (\(y\)) curve (Lande, DeVries, and Walla 2000), and the variance of species composition (Lande 1996).
Here we show the equivalence of Simpson’s index and the variance of species composition. First, we reimagine community X as collections of individuals comprising different species identities. We we create a pretend community of six individuals (rows) and 3 species (columns). Somewhat oddly, we identify the degree to which each individual is comprised of each species; in this case, individuals can be only one species.84 Here we let two individuals be each species.
X <- matrix(0, nrow=14, ncol=3,
dimnames=list(NULL, c("A", "B", "C")))
X[1:10,1] <- 1
X[11:13,2] <- 1
X[14,3] <- 1
t(X)## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12] [,13] [,14]
## A 1 1 1 1 1 1 1 1 1 1 0 0 0 0
## B 0 0 0 0 0 0 0 0 0 0 1 1 1 0
## C 0 0 0 0 0 0 0 0 0 0 0 0 0 1We transposed the matrix, so that individuals are columns and species membership or identity is in rows. The first individual belongs to species A, etc. We can plot these individuals in community space, if we like (Fig. 14.5).
library(scatterplot3d)
X3D <- scatterplot3d(jitter(X, .1), type='h', angle=60, pch=rep(1:3, c(10,3,1)) )
X3D$points3d(x=10/14, y=3/14, z=1/14, type='h', pch=19, cex=2)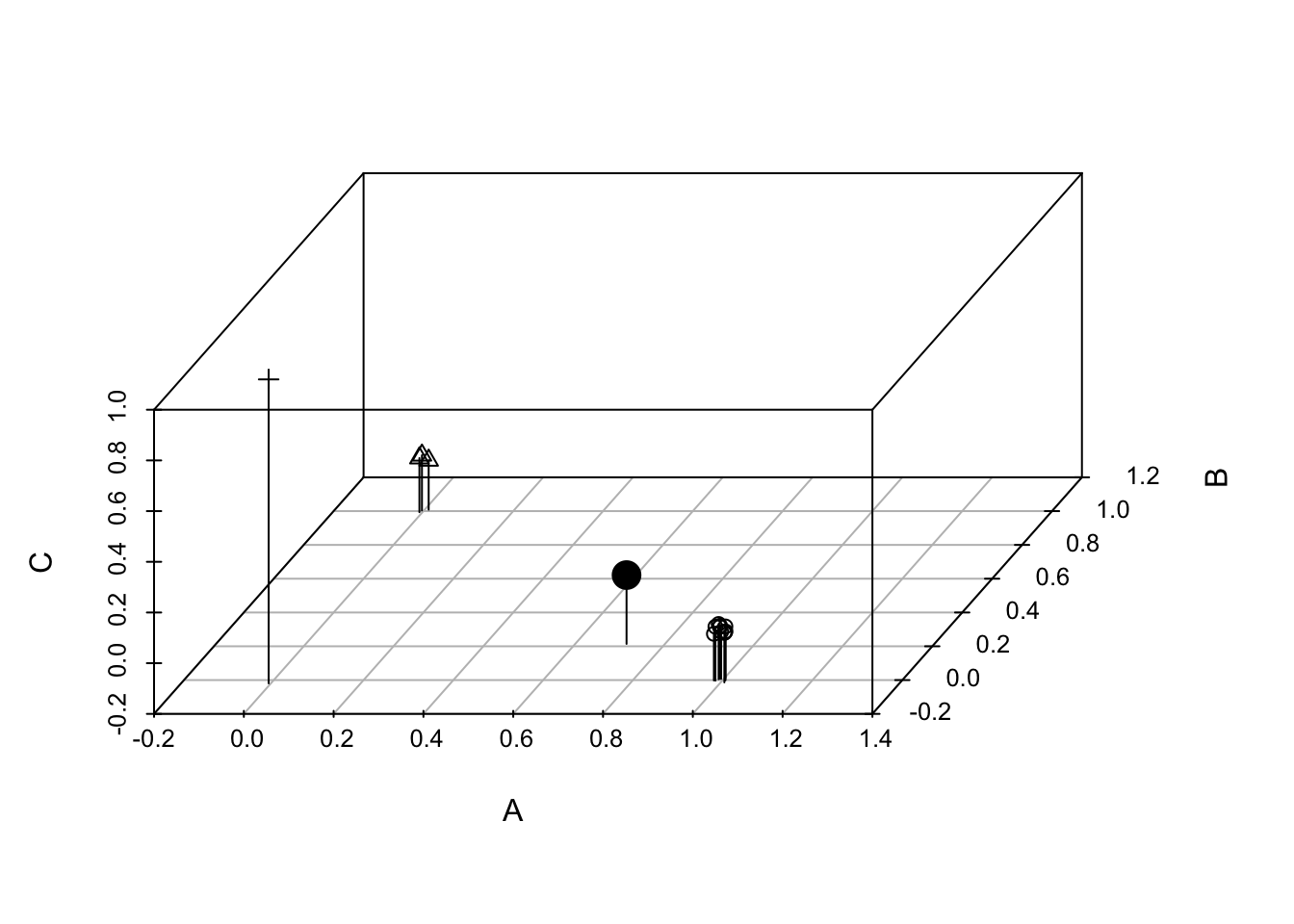
Figure 14.5: Each of 14 individuals in a three species community, plotted in ‘compsition space’. The large black dot is the multivariate mean, or centroid, which is the center of gravity in this composition space. Simpson’s diversity is the variance of species composition of individuals (Lande 1996).
Next we can calculate the centroid, or multivariate mean. It is merely the vector of species means.
(centroid1 <- colMeans(X))## A B C
## 0.71428571 0.21428571 0.07142857Given this centroid, we begin to calculate a variance by (i) subtracting each species vector (0s, 1s) from its mean, (ii) squaring each of these deviates, and (3) summing to get the sum of squares.
## [1] 6.142857We then divide this sum by the number of individuals that were in the community (\(N\))
SS/14## [1] 0.4387755When you compare this to the calculation of Simpson’s complement below, you will find that they are the same. Further, the finite sample size correction is the same for both.
Simpson’s complement diversity index converges quickly with increasing sample size, making it the most reliable index for small sample sizes. It also has an unbiased estimator (Lande 1996), which is \[\hat{S_c} = \frac{N}{N-1}(1-D)\]
Simpson’s inverse diversity index is the inverse of dominance, \[S_I = \frac{1}{D}\] This value could be considered the ‘effective’ number of species, which discounts the rarest species (Nee 2005) and which is closely allied to population genetics theory as one definition for the ‘effective number of alleles’ (Nee 2005; Crow and Kimura 1970).
We can calculate these by defining our own functions. We then create a grouped data frame and calculate our summary statistics, using the dplyr package (part of tidyverse).
Sc <- function(x) {
p <- x/sum(x)
1-sum(p^2)
}
Si <- function(x) {
p <- x/sum(x)
1/sum(p^2)
}
dfg <- group_by(df, comm) # group by community
# calculate indices for each community type.
summarize(dfg,
richness = length( n[n>0]),
H = shannon(n),
Sc = Sc(n),
Si = Si(n)
)## # A tibble: 2 × 5
## comm richness H Sc Si
## <chr> <int> <dbl> <dbl> <dbl>
## 1 X 3 0.759 0.439 1.78
## 2 Y 4 1.24 0.684 3.16In this case, all of these indices agree with each other, and our intuition: community Y is more ‘diverse’.
These diversity indices are actually directly related to each other — they comprise estimates of entropy, the amount of disorder or the multiplicity of possible states of a system, that are directly related via a single constant (Keylock 2005). However, an important consequence of their differences is that richness depends most heavily on rare species, Simpson’s complement depends most heavily on the relative abundance of common species, and Shannon-Wiener stands somewhere between the two.
14.5 Rarefaction and total species richness
Rarefaction is the process of generating the relationship between the number of species vs. the number of individuals in a sample. It is typically determined by randomly resampling individuals (N. J. Gotelli and Colwell 2001). Rarefaction allows direct comparison of the richness of two samples, corrected for numbers of individuals. This is particularly important because richness depends so heavily on the number of individuals in a sample. Thus rarefaction finds the general relation between the number of species vs. the number of individuals, and is limited to less than or equal to the number of species you actually observed. A related curve is the species-accumulation curve or collector’s curve, but this is simply a useful but haphazard accumulation of new species (a cumulative sum) as the investigator samples new individuals.
Another issue that ecologists face is trying to estimate the true number of species in an area, given the samples collected. This number of species would be larger than the number of species you observed, and is often referred to as total species richness or asymptotic richness. Samples almost always find only a subset of the species present in an area or region, but we might prefer to know how many species are really there, in the general area we sampled. There are many ways to do this, and while some are better than others, none is perfect. These methods estimate minimum numbers of species, and assume that the unsampled areas are homogeneous and similar to the sampled areas.
Before using these methods seriously, the inquisitive reader should consult (N. J. Gotelli and Colwell 2001; Magurran 2004) and references at http://viceroy.eeb.uconn.edu/EstimateS. Below, we briefly explore an example in R.
14.5.1 An example of rarefaction and total species richness
Let us sample a seasonal tropical rainforest on Barro Colorado Island (BCI) Our goal will be to provide baseline data for later comparison to other such studies.
We will use some of the data from a 50 ha plot of neotropical forest that is included in the vegan package (Oksanen et al. 2019). We will pretend that we sampled every tree over 10 cm DBH,85 in each of 10 plots scattered throughout the 50 ha area. What could we say about the forest within which the plots were located? We have to consider the scale of the sampling. Both the experimental unit and the grain are the 1 ha plots. Imagine that the plots were scattered throughout the 50 ha plot, so that the extent of the sampling was a full 50 ha (sensu Wiens 1989).
First, let’s pretend we have sampled 10 1 ha plots by extracting the samples out of the larger dataset.
## Abarema.macradenia Adelia.triloba
## 5 0 1
## 10 1 0
## 15 0 2
## 20 0 0
## 25 0 0This data set has plots in rows and species names in columns; the data are numbers of individuals of each species (columns) in each plot (rows).
Next, we total the numbers for each species, pooling all plots together. We sum the columns, and remove zeroes.
N <- colSums(bci)
N <- N[N>0]Based on this sample, we find that the species richness in all our samples pooled is the tally of all non-zero species.
sum(N>0)## [1] 179Our goal is to estimate the number of species in the area. For that we need estimators of total species richness, if we can assume that the surrounding forest is homogeneous. First, we’ll use abundance-based coverage estimators, ACE and Chao 1, that appear to give reasonable estimates (Magurran 2004).
estimateR(N)## S.obs S.chao1 se.chao1 S.ACE se.ACE
## 179.000000 202.000000 12.763215 190.638313 6.779286Here we see the observed number of species and two estimators, with standard errors.
Next we use a frequency-based estimator, Chao 2, where the data only need to be presence/absence, and for which we also need multiple sample plots. By using multiple plots, we get some idea of of how rare some species are and use that to estimate how many more rare species there might be which are unsampled.
(chaoF <- specpool(bci))## Species chao chao.se jack1 jack1.se jack2 boot boot.se n
## All 179 202.4321 11.99975 203.3 8.606393 214.9444 190.7196 5.146857 10We also get a jackknifed estimate. All of these give some estimate as to the minimum true number of species in an area around our samples.
Typically the use of these estimators is accompanied by some form of rarefaction. To perform rarefaction, we need to select numbers of individuals for which we want rarefied samples. We will use multiples of 500 and also the total number of individuals in the sample. We then use a built-in function to draw species at random for these numbers of individuals, that is, perform rarefaction.
Next we want to graph it, with a few bells and whistles. We set up the graph of the 10 plot, individual-based rarefaction, and leave room to graph total richness estimators as well (Fig. 14.6).
plot(no.of.inds , rar3[1,], ylab="Species Richness", axes=FALSE,
xlab="No. of Individuals", type='n', ylim=c(0,250),
xlim=c(500,5900) )
# estimate
lines(no.of.inds, rar3[1,], type='b')
# approximate confidence intervals
lines(no.of.inds, rar3[1,]+2*rar3[2,], lty=3)
lines(no.of.inds, rar3[1,]-2*rar3[2,], lty=3)
axis(1, at=1:5*1000); axis(2); box();
text(2500, 200, "Individual-based rarefaction (10 plots)")
# add the Chao 2 estimator
segments(5500, chaoF[1,'chao'] - 2*chaoF[1,'chao.se'],
5500, chaoF[1,'chao'] + 2*chaoF[1,'chao.se'],
lwd=3, col='darkgrey')
text(5500, 150, "Chao 2 estimate", srt=90, adj=c(1,.5) )
points(5800, dim(BCI)[2], pch=19, cex=1.2)
text(5800, 150, "Obs. S in 50 ha", srt=90, adj=c(1,.5) )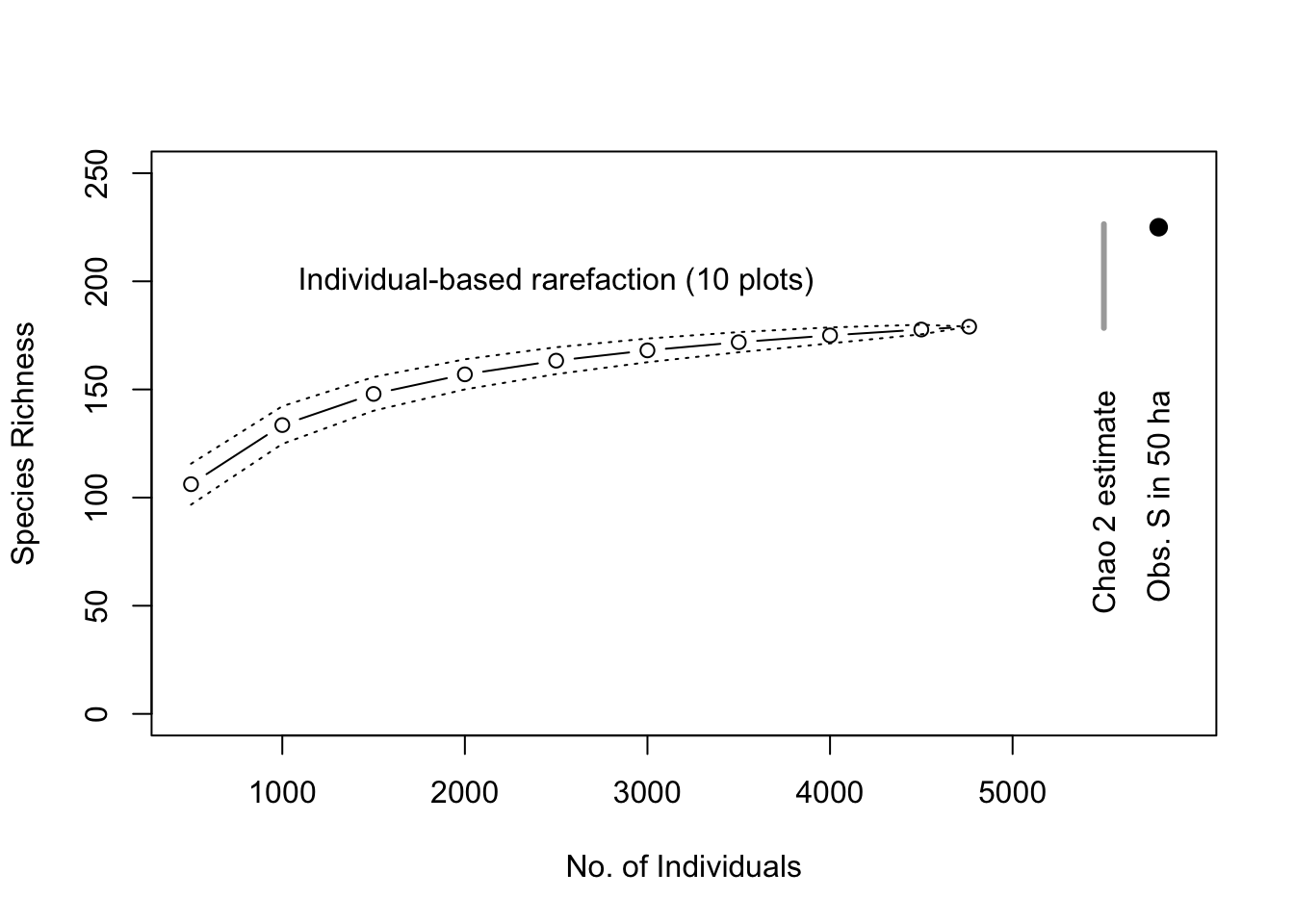
Figure 14.6: Baseline tree species richness estimation based on ten 1 ha plots, using individual-based rarefaction. We also include the Chao 2 total richness estimators and the observed total tree richness in the 50 ha plot for comparison (black dot).
This shows us that the total richness estimator did not overestimate the total number of species within the extent of this relatively homogenous sample area (Fig. 14.6). In that sense, these estimators are estimating the minimum total number of species and are thus conservative.
Simpson’s diversity provides an interesting description of a rarifcation curve. The expected number of species in a sample of \(N\) individuals drawn from a community with total species richness \(S\), is \[\mathrm{E}[\hat{S}] = S-\sum_{i=1}^S (1-p_i)^N\] where \(p_i\) is the frequency or relative abundance of species \(i\). The initial slope of the rarifaction curve, is \[\frac{\Delta \mathrm{E}[\hat{S}]}{\Delta N}\] where \(\Delta N = 2-1=1\). The numerator is is the difference between the expected number of species in a sample of two vs. one individual. We can work through this here, if only to remind ourselves of rules about working with sums, and that the sum of all \(p_i\) is 1, by definition. Also, it helps to realize that when \(N=1\), \(E[\hat{S}] = 1\).
\[\begin{align*} \Delta E[\hat{S}] &= S-\sum_{i=1}^S(1-p_i)^2 - \left( S-\sum_{i=1}^S(1-p_i) \right)\\ &= S - \sum_{i=1}^S(1-2p_i+p_i^2) - 1\\ &= S - \sum_{i=1}^S(1) + \sum_{i=1}^S (2p_i) - \sum_{i=1}^S(p_i^2) - 1\\ &= S - S + 2 - \sum_{i=1}^S(p_i^2) - 1\\ & = 1 - \sum_{i=1}^S(p_i^2) \end{align*}\]
So, all else being equal, Simpson’s diversity is an important part of the shape of the species accumulation curve. And that slope is the probability that two individuals drawn at random belong to two different species. :)
14.6 Distributions
The above estimators for total species richness each assume that species abundances follow some sort of distribution where some species are common, and most are rare. Here we explore some particular types of distributions that have been used to quantify this aspect of community structure.
Like any other vector of numbers, we can make a histogram of species abundances. As an example, here we make a histogram of bci tree densities, where each species has its own density (left, Fig. 14.7). This shows us what is patently true for nearly all ecological communities, that most species are rare.
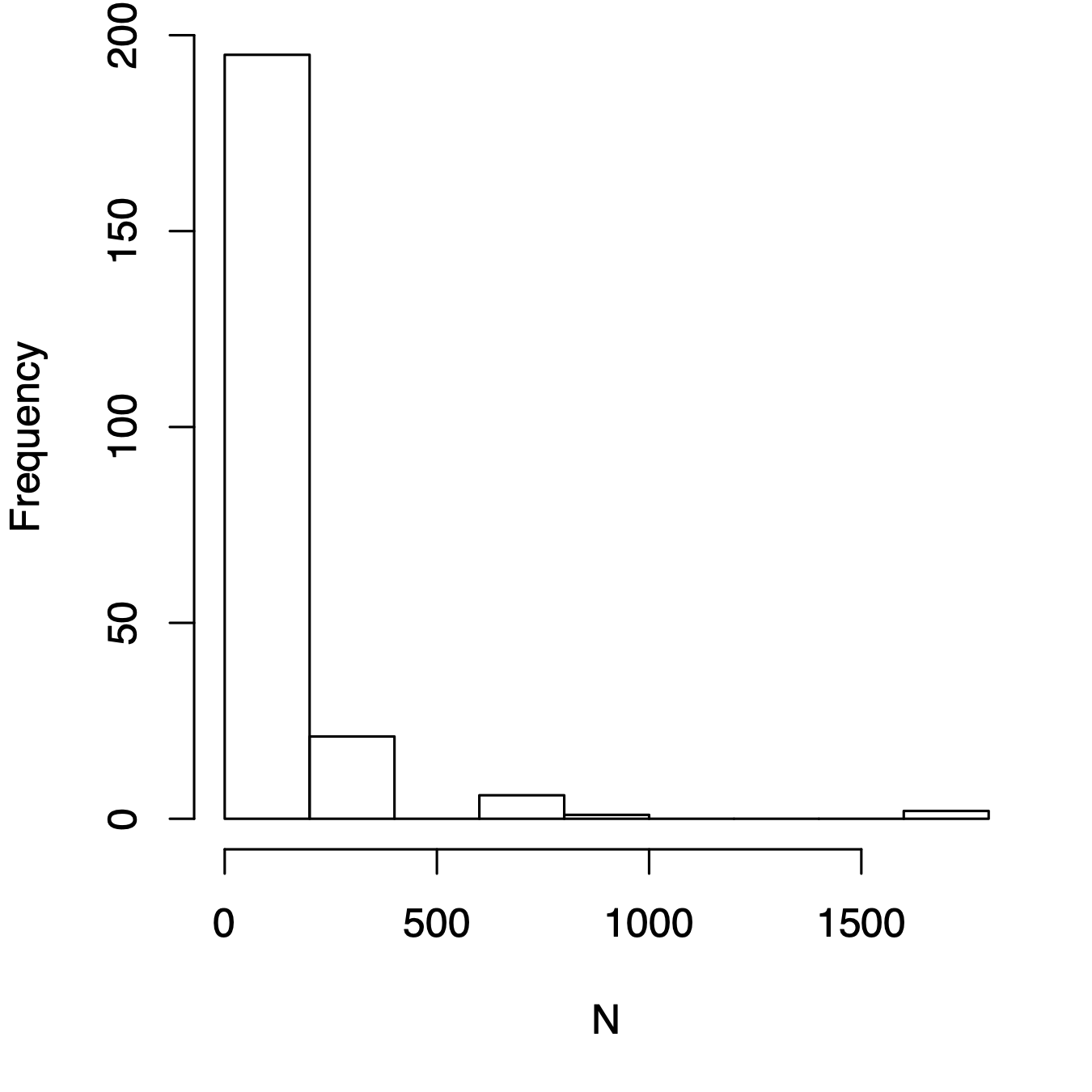
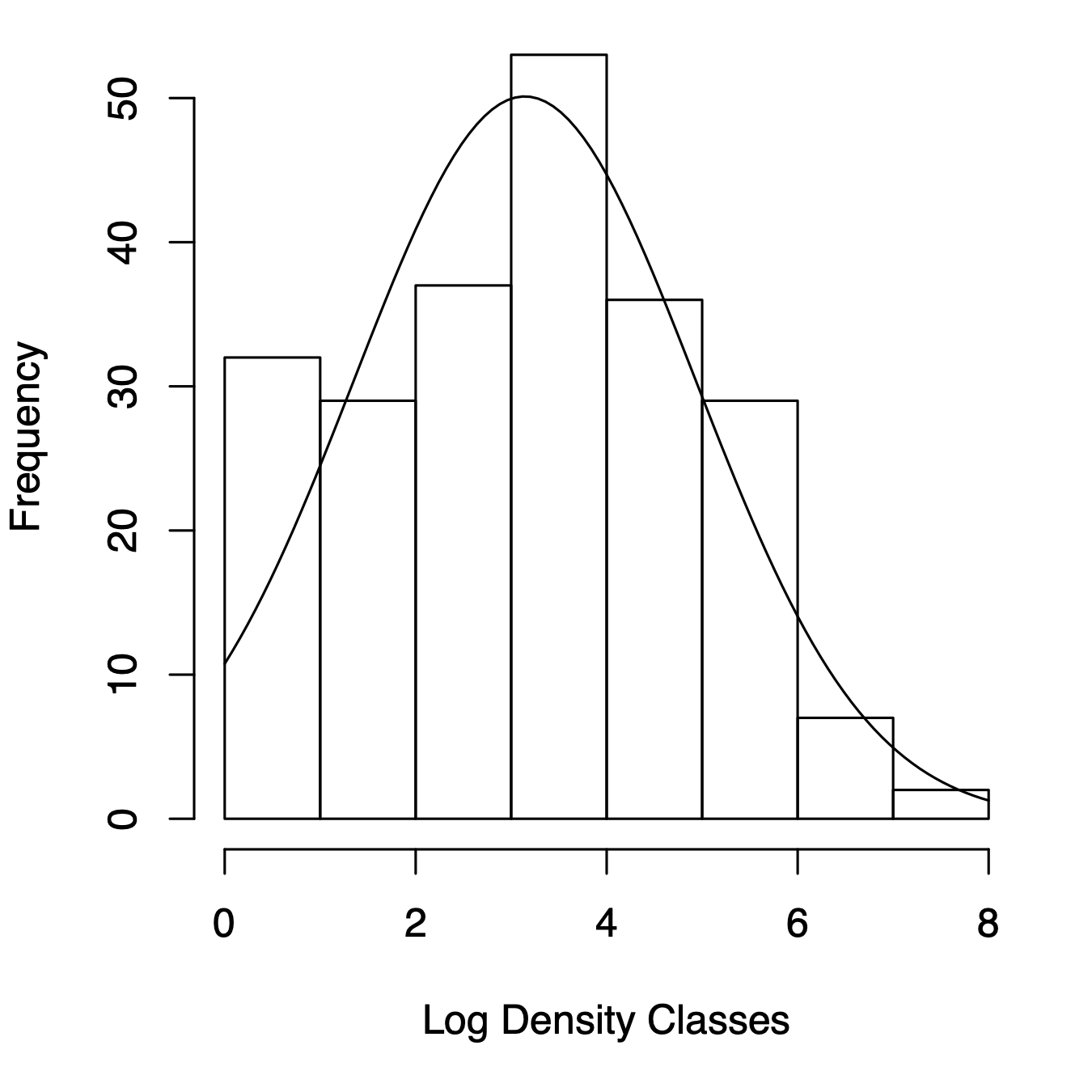
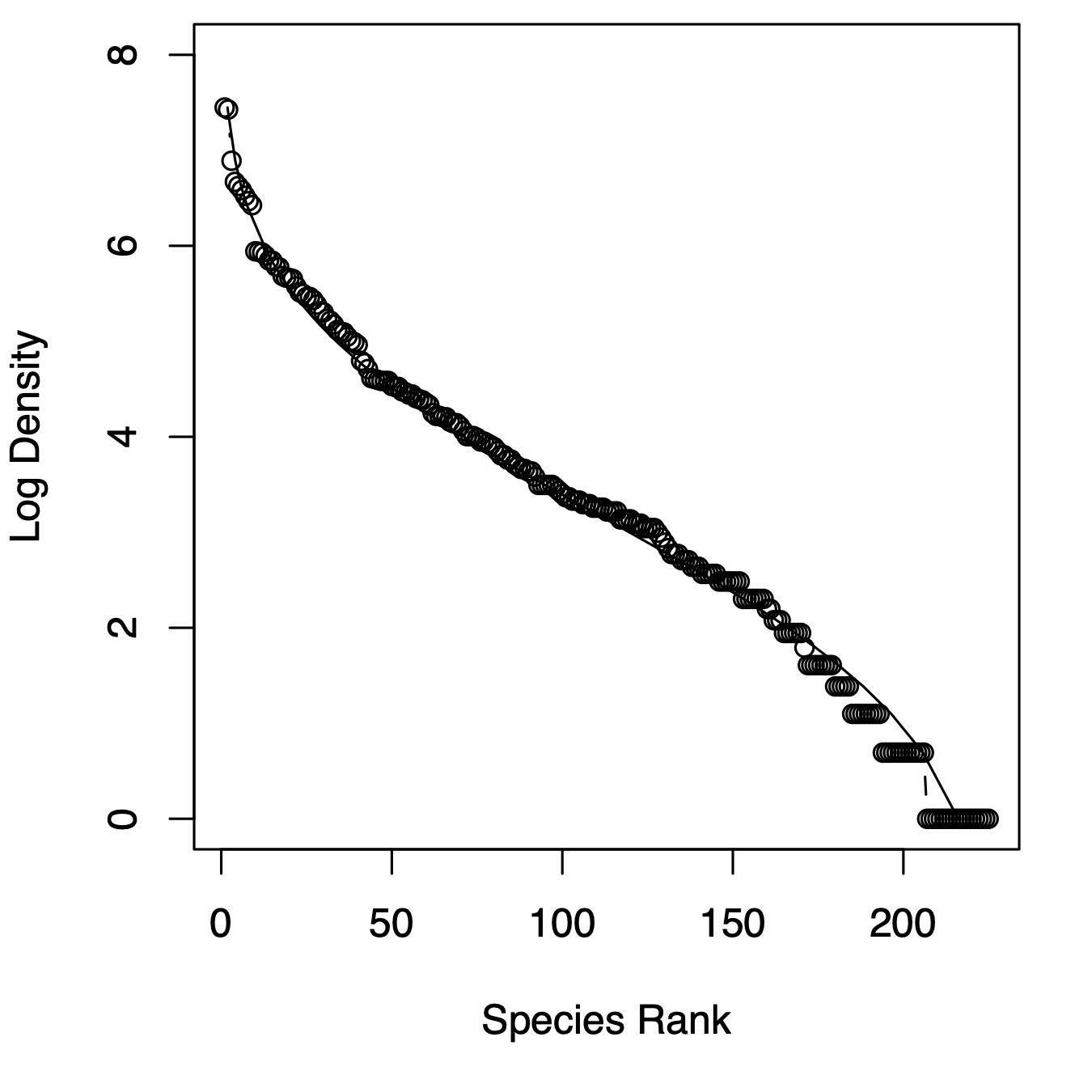
Figure 14.7: Three related types of distributions of tree species densities from Barro Colorado Island. Left, histogram of raw data; center, the species–abundance distribution, which is a histogram of log-transformed abundances, accompanied here by the normal probability density function; right, the rank–abundance distribution, as typically presented with the log-transformed data, with the complement of the cumulative probability density function (1-pdf). Normal distributions were applied using the mean and standard deviation from the log-transformed data, times the total number of species.
14.6.1 Log-normal distribution
Given general empirical patterns, that most species are rare, Frank Preston (Preston 1948, 1962) proposed that we describe communities using the logarithms of species abundances (center, Fig. 14.7).86 This often reveals that a community can be described approximately with the normal distribution applied to the log-transformed data, or the log-normal ditribution. We can also display this as a rank–abundance distribution (right, Fig. 14.7). To do this, we assign the most abundant species as rank = 1, and the least abundant has rank = \(S\), in a sample of \(S\) species, and plot log-abundance vs. rank.
R. M. May (1975) described several ways in which common processes may drive log-normal distributions, and cause them to be common in data sets. Most commonly cited is to note that log-normal distributions arise when each observation (i.e., each random variable) results from the product of independent factors. That is, if each species’ density is determined by largely independent factors which act multiplicatively on each species, the resulting densities would be log-normally distributed. In the process known as ecological drift, pure demographic stochasticity where all species have equal fitness will drive a log-normal-like distribution (see later section on neutral theory).
Well over a dozen other types of abundance distributions exist to describe abundance patterns, other than the log-normal (Magurran 2004). They can all be represented as rank–abundance distributions.
14.6.2 Other distributions
The geometric distribution, also known as the niche preemption distribution, reflects a simple idea, wherein each species pre-empts a constant fraction of the remaining niche space (R. M. May 1975; Motomura 1932). For instance, if the first species uses 20% of the niche space, the second species uses 20% of the remaining 80%, etc. The frequency of the \(i\)th most abundant species is \[N_i = \frac{N_T}{C}d\left(1-d\right)^{i-1}\] where \(d\) is the abundance of the most common species, and \(C\) is just a constant to make \(\sum N_i = N_T\), where \(C=1-\left(1-d\right)^{S_T}\). Thus this describes the geometric rank–abundance distribution.
The log-series distribution (Fisher, Corbet, and Williams 1943) describes the expected frequency of species with \(n\) individuals, \[\begin{equation} \tag{14.1} F\left(S_n\right) = \frac{\alpha x^n}{n} \end{equation}\] where \(\alpha\) is a constant that represents diversity (greater \(\alpha\) means greater diversity); the \(\alpha\) for a diverse rainforest might be 30–100. The constant \(x\) is a fitted free parameter, and it is always true that \(0.9 < x < 1.0\) and \(x\) increases toward 0.99 as \(N/S \to 20\) (Magurran 2004). \(x\) can be estimated from \(S/N=[(1-x)/x] \cdot [-\ln(1-x)]\). Note that this is not described as a rank–abundance distribution, but species abundances and ranks can nonetheless be plotted in that manner (R. M. May 1975).
We can estimate Fisher’s alpha using optimal.theta() in the untb library.
The log-series rank–abundance distribution is thus a bit of a pain, where we are relying on the standard exponential integral (R. M. May 1975), \(E_1(s) = \int_s^\infty exp(-t)/t\,dt\). Given a range of \(N\), we calculate ranks as \[F\left(N\right) = \alpha \int_s^\infty exp(-t)/t\,dt\] where we can let \(t=1\) and \(s = N \log \left(1 + \alpha/N_T\right)\). We code for this below.
The log-series distribution has the interesting property that the total number of species in a sample of \(N\) individuals would be \(S_T = \alpha \log(1+N/\alpha)\). The parameter \(\alpha\) is sometimes used as a measure of diversity. If your data are log-series distributed, then \(\alpha\) is approximately the number of species for which you expect 1 individual, because \(x\approx 1\). Two very general theories predict a log-series distribution, including neutral theory, and maximum entropy. Oddly, these two theories both predict a log-series distribution, but make opposite assumptions about niches and individuals (see next section).
MacArthur’s broken stick distribution is a classic distribution that results in a very even distribution of species abundances (R. H. MacArthur 1957). The expected number of individuals of each species \(i\) is \[N_i = \frac{N_T}{S_T}\sum_{n=i}^{S_T}\frac{1}{n}\] where \(N_T\) and \(S_T\) are the total number of individuals and species in the sample, respectively. MacArthur described this as resulting from the simultaneous breakage of a stick at random points along the stick. The resulting size fragments are the \(N_i\) above. MacArthur’s broken stick model is thus both a stochastic and a deterministic model. It has a simulation of stick breakage that is the direct analogue of the deterministic analytical expression.
Other similarly tactile stick-breaking distributions create a host of different rank–abundance patterns (M. Tokeshi 1999). In particular, the stick can be broken sequentially, first at one random point, then at a random point along one of two newly broken fragments, then at an additional point along any one of the three broken fragments, etc., with \(S_T-1\) breaks creating \(S_T\) species. The critical difference between the models then becomes how each subsequent fragment is selected. If the probability of selecting each fragment is related directly to its size, then this becomes identical to MacArthur’s broken stick model. On the other hand, if each subsequent piece is selected randomly, regardless of its size, then this results in something very similar to the log-normal distribution (Sugihara 1980; Mutsunori Tokeshi 1990). Other variations on fragment selection generate other patterns (M. Tokeshi 1999).
Here we plot the empirical rank-abundance distribution of all of the BCI data from this census of the 50 ha plot, along with several fitted distributions. They are fit using the radfit function in the vegan package. We then add the log series distribution.
# fit the distributions
N <- rev(sort(colSums(BCI)))
# get the expected ranks for the log series distribution
# standard exponential integral
sei <- function(t = 1) exp(-t)/t
alpha <- optimal.theta(N)
Nt <- sum(N)
rank.logseries <- sapply(N, function(x) {
n <- x * log(1 + alpha/Nt )
f <- integrate(sei, n, Inf)
fv <- f[["value"]]
alpha * fv } )
mod <- radfit(N)
par(mar=c(5,4,1,1))
plot(mod)
lines(rank.logseries, N, lty=2)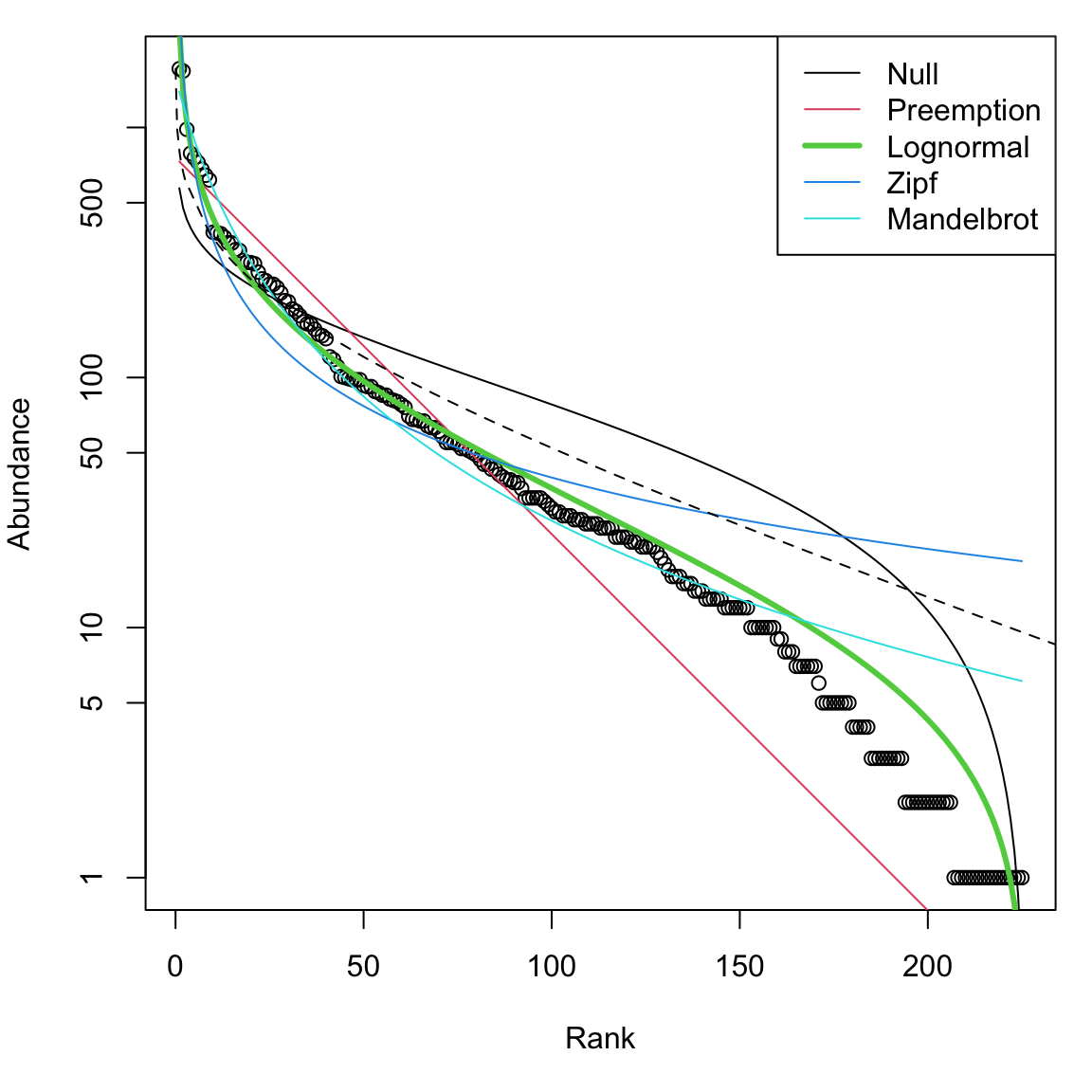
Figure 14.8: Entire BCI rank abundance distribution with several fitted models. ‘Null’ is the broken stick distribution, and the dashed line is the log series.
14.6.3 Pattern vs. process
Note the resemblance between stick-breaking and niche evolution — if we envision the whole stick as all of the available niche space, or energy, or limiting resources, then each fragment represents a portion of the total occupied by each species. Thus, various patterns of breakage act as models for niche partitioning and relative abundance patterns. Other biological and stochastic processes create specific distributions. For instance, completely random births, deaths, migration, and speciation will create the log-series distribution and the log-normal-like distributions (see neutral theory below). We noted above that independent, multiplicatively interacting factors can create the log-normal distribution.
Although it is intriguing to ponder the processes that can generate particular patterns, we cannot infer definitively the underlying processes from the patterns we observe. That is because different processes can generate the same pattern. Nonetheless, particuar patterns can suggest certain hypotheses about the underlying processes. Many ecologists argue that describing patterns and predicting them are the most important goals of ecology (Peters 1988), while others argue that understanding the mechanistic process is the only important goal. Regardless, both of these camps would agree that we can’t draw firm conclusions about processes based solely on patterns — nowhere in ecology has this fallacy been more prevalent than with abundance distributions (Hairston Sr. 1991).
14.7 Neutral Theory of Biodiversity and Biogeography
One model of abundance distributions is particularly important, and we elaborate on it here. It is referred to variously as the unified neutral theory of biodiversity and biogeography (Hubbell 2001) or often ‘neutral theory’ or ‘eccological drift’ for short. Neutral theory is important because it does much more than most other models of abundance distributions. It is a testable theory that makes quantitative predictions across several levels of organization, for both evolutionary and ecological processes.
Just as evolutionary biology has neutral theories of gene and allele frequencies, ecology has neutral theories of population and community structure and dynamics (Bell 2000; Caswell 1976; Hubbell 2001). Neutral communities of species are computationally and mathematically related and often identical to models of genes and alleles (Ewens 2004) (Table 14.1). Thus, lessons you have learned about genetic drift often apply to neutral models of communities. Indeed, neutral ecological dynamics at the local scale are often referred to as ecological drift, and populations change via demographic stochasticity.87
Stephen Hubbell proposed his unified neutral theory of biodiversity and biogeography (hereafter NTBB, (Hubbell 2001)) as a null expectation of the dynamics of individuals, to help explain relative abundances of tropical trees. Hubbell describes it as a direct descendant of MacArthur and Wilson’s theory of island biogeography (Robert H. MacArthur and Wilson 1963; R. H. MacArthur and Wilson 1967) (see below, species–area relations). Hubbell proposed it both as a null hypothesis and also — and this is the controversial part — as a model of community dynamics that closely approximates reality.

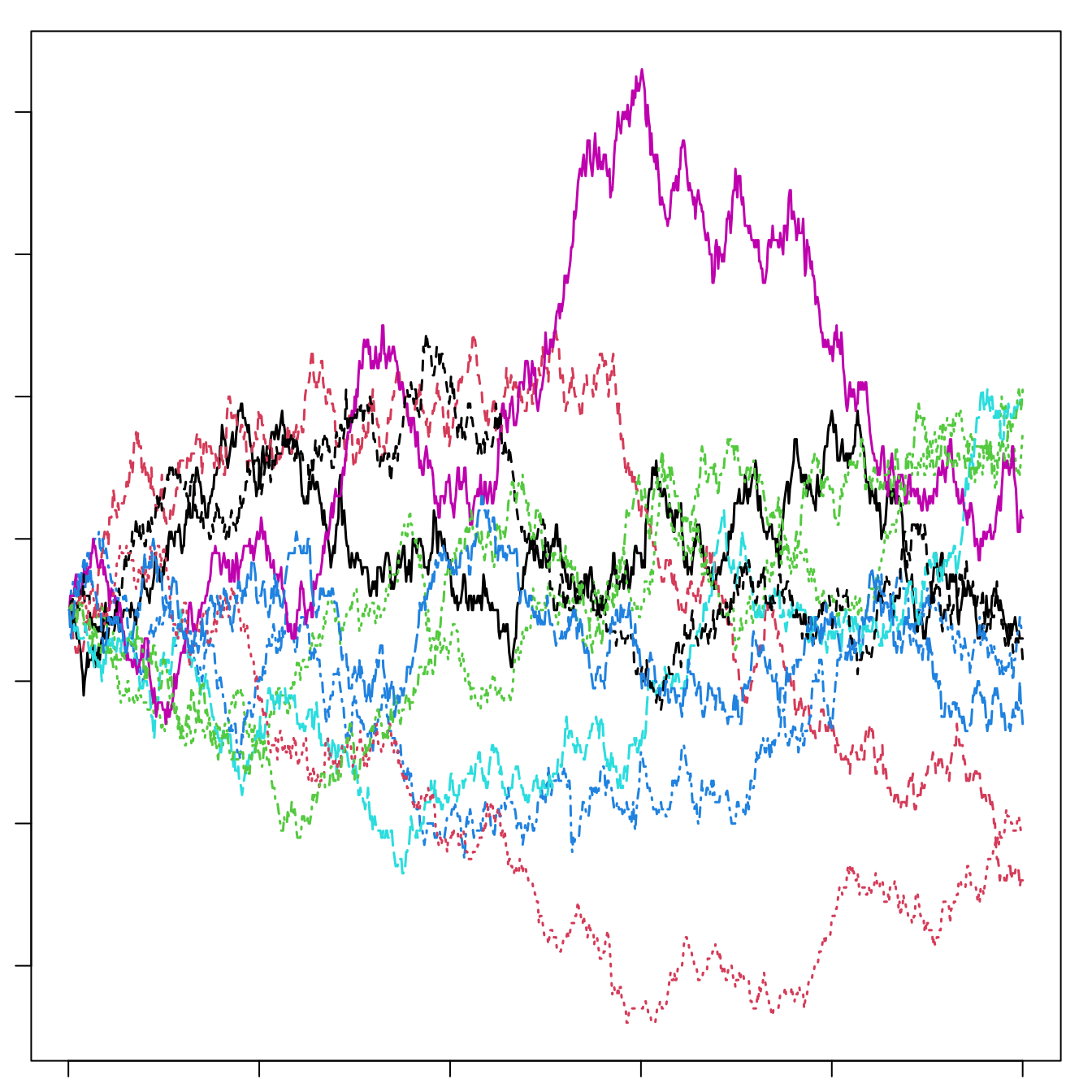
Figure 14.9: Left: A local community of forest canopy trees (small box) nested inside part of the metacommunity of a tropical forest. The true metaccommunity would extend far beyond the boundaries of this figure to include the true potential source of propagules. Shades of grey indicate different species. The local community is a sample of the larger community (such as the 50 ha forest dynamics plot on BCI) and receives migrants from the metacommunity. Mutation gives rise to new species in the metacommunity. For a particular local community, such as a 50 ha plot on an island in the Panama canal, the metacommunity will include not only the surrounding forest on the island, but also Panama, and perhaps much of the neotropics. Right: Neutral ecological drift. Ten species, each of 90 individuals, undergo random walks within a finite local community, with no immigration. Here, one generation is equal to nine deaths and nine births. Note the slow decline in unevenness — after 1000 deaths, no species has become extinct.
The relevant world of the NTBB is a metacommunity (left, Fig. 14.9), that is, a collection of local communities connected by dispersal (Leibold et al. 2004).88 The metacommunity is populated entirely by individuals that are functionally identical. The NTBB is a theory of the dynamics of individuals, modeling individual births, deaths, migration and mutation. It assumes that within a guild, such as late successional tropical trees, species are essentially neutral with respect to their fitness, that is, they exhibit fitness equivalence. This means that the probabilities of birth, death, mutation and migration are identical for all individuals. Therefore, changes in population sizes occur via random walks, that is, via stochastic increases and decreases with time step (right, Fig. 14.9). Random walks do not imply an absence of competition or other indirect enemy mediated negative density dependence. Rather, competition is thought to be diffuse, and equal among individuals. We discuss details of this in the context of simulation. Negative density dependence arises either through a specific constraint on the total number of individuals in a community (Hubbell 2001), or as traits of individuals related to the probabilities of births, deaths, and speciation (Volkov et al. 2005).
A basic paradox of the NTBB, is that in the absence of migration or mutation, diversity gradually declines to zero, or monodominance. A random walk due to fitness equivalence will eventually result in the loss of all species except one. However, the loss of diversity in any single local community is predicted to be very, very slow, and is countered by immigration and speciation (we discuss more details below). Thus, species do not increase deterministically when rare — this makes the concept of coexistence different than the stable coexistance criteria discussed in previous chapters. Coexistance here is not stable but rather only a stochastic event with a limited time horizon which is balanced by the emergence of new species.
If all communities are thought to undergo random walks toward monodominance, how is diversity maintained in any particular region? Two factors maintain species in any local community. First, immigration into the local community from the metacommunity can bring in new species. Even though each local community is undergoing a random walk toward monodominance, each local community may become dominated by any one of the species in the pool because all species have equal fitness. Thus separate local communities are predicted to become dominated by different species, and these differences among local communities help maintain diversity in the metacommunity landscape.89 Second, at longer time scales and larger spatial scales, speciation (i.e., mutation and lineage-splitting) within the entire metacommunity maintains biodiversity. Mutation and the consequent speciation provide the ultimate source of variation. Random walks toward extinction in large communities are so lengthy that the extinctions are balanced by speciation.
Introducing new symbols and jargon for ecological neutral theory, we state that the diversity of the metacommunity, \(\theta\), is a function of the number of individuals in the metacommunity, \(J_M\), and the per capita rate at which new species arise (via mutation) \(\nu\) (\(\theta = 2J_M \nu\); Table 14.1). A local community undergoes ecological drift; drift causes the slow loss of diversity, which is balanced by a per capita (\(J_L\)) immigration rate \(m\).
| Property | Ecology | Evolution |
|---|---|---|
| Entire System (size) | Metacommunity (\(J_M\)) | Population (\(N\)) |
| Nested subsystem (size) | Local community (\(J_L\)) | Subpop. or Deme (\(N\)) |
| Smallest neutral system unit | Individual organism | Individual gene |
| Diversity unit | Species | Allele |
| Stochastic process | Ecological drift | Genetic drift |
| Generator of diversity (rate symbol) | Speciation (\(\nu\)) | Mutation (\(\mu\)) |
| Fundamental diversity number | \(\theta \approx 2J_M\nu\) | \(\theta \approx 4N\mu\) |
| Fundamental dispersal number | \(I \approx 2J_L m\) | \(\theta \approx 4Nm\) |
| Relative abundance distribution (\(\Phi \left(x \right)\)) | \(\frac{\theta}{x}\left(1-x\right)^{\theta - 1}\) | \(\frac{\theta}{x}\left(1-x\right)^{\theta - 1}\) |
| Time to common ancestor | \(\frac{-J_M x}{1-x}\log x\) | \(\frac{-N x}{1-x} \log x\) |
It turns out that the abundance distribution of an infinitely large metacommunity is Fisher’s log-series distribution, and that \(\theta\) of neutral theory is \(\alpha\) of Fisher’s log-series (Alonso, Etienne, and McKane 2006; Leigh E. G. 1999; Volkov et al. 2003). However, in any one local community, random walks of rare species are likely to include zero, and thus become extinct in the local community by chance alone. This causes a deviation from Fisher’s log-series in any local community by reducing the number of the the rarest species below that predicted by Fisher’s log-series. In particular, it tends to create a log-normal–like distribution, much as we often see in real data (Fig. 14.7). These theoretical findings and their match with observed data are thus consistent with the hypothesis that communities may be governed, in some substantive part, by neutral drift and migration.
Both theory and empirical data show that species which coexist may be more similar than predicted by chance alone (Leibold and McPeek 2006), and that similarity (i.e., fitness equality) among species helps maintain higher diversity than would otherwise be possible (Chesson 2000a). Chesson makes an important distinction between stabilizing mechanisms, which create attractors, and equalizing mechanisms, which reduce differences among species, slow competitive exclusion and facilitate stabilization (Chesson 2000a).
The NTBB spurred tremendous debate about the roles of chance and determinism, of dispersal-assembly and niche-assembly, of evolutionary processes in ecology, and how we go about ‘doing community ecology’ (see, e.g., articles in Functional Ecology, 19(1), 2005; Ecology, 87(6), 2006). This theory in its narrowest sense has been falsified with a few field experiments and observation studies (Clark and McLachlan 2003; Wootton and Emmerson 2005). However, the degree to which stochasticity and dispersal versus niche partitioning structure communities remains generally unknown. Continued refinements and elaboration (e.g., Volkov et al. (2007)) seem promising, continuing to intrigue scientists with different perspectives on natural communities Latimer, Silander, and Cowling (2005).
Even if communities turn out to be completely non-neutral, NTBB provides a baseline for community dynamics and patterns that has increased the rigor of evidence required to demonstrate mechanisms controlling coexistence and diversity. As Alonso, Etienne, and McKane (2006) state, “… good theory has more predictions per free parameter than bad theory. By this yardstick, neutral theory fares fairly well.” (see also Marquet et al. 2014).
14.7.1 Different flavors of neutral communities
Neutral dynamics in a local community can be simulated in slightly different ways, but they are all envisioned as some type of random walk. A random walk occurs when individuals reproduce or die at random, with the consequence that each population increases or decreases by chance.
The simplest version of a random walk assumes that births and deaths and consequent increases and decreases in population size are equally likely and equal in magnitude. A problem with this type of random walk is that a community can increase in size (number of individuals) without upper bound, or can disappear entirely, by chance. We know this doesn’t happen, but it is a critically important first step in conceptualizing a neutral dynamic (Caswell 1976).
Hubbell added another level of biological reality by fixing the total number of individuals in a local community, \(J_L\), as constant. When an individual dies, it is replaced with another individual, thus keeping the population size constant. Replacements come from within the local community with probability \(1-m\), and replacements come from the greater metacommunity with probability \(m\). The dynamics of the metacommunity are so slow compared to the local community that we can safely pretend that it is fixed, unchanging.
Volkov et al. (2003) took a different approach by assuming that each species undergoes independent biased random walks. We imagine that each species undergoes its own completely independent random walk, as if it is not interacting with any other species. The key is that the birth rate, \(b\), is slightly less than the death rate, \(d\) — this bias toward death gives us the name biased random walk. In a deterministic model with no immigration or speciation, this would result in a slow population decline to zero. In a stochastic model, however, some populations will increase in abundance by chance alone. Slow random walks toward extinctions are balanced by speciation in the metacommunity (with probability~\(\nu\)).
If species all undergo independent biased random walks, does this mean species don’t compete and otherwise struggle for existence? No. The reason that \(b < d\) is precisely because all species struggle for existence, and only those with sufficiently high fitness, and which are lucky, survive. Neutral theory predicts that it is these species that we observe in nature — those which are lucky, and also have sufficiently high fitness.
In the metacommunity, the average number of species, \(\langle \phi_n^M \rangle\), with population size \(n\) is \[\begin{equation} \tag{14.2} \langle \phi_n^M \rangle = \theta \frac{x^n}{n} \end{equation}\] where \(x = b/d\), and \(\theta = 2J_M\nu\) (Volkov et al. 2003). The \(M\) superscript refers to the metacommunity, and the angle brackets indicate merely that this is the average. Here \(b/d\) is barely less than one, because it a biased random walk which is then offset by speciation, \(\nu\). Now we see that this is exactly Fisher’s log-series distribution (14.1), where that \(x=b/d\) and \(\theta = \alpha\). Volkov et al. thus show that in a neutral metacommunity, \(x\) has a biological interpretation.
The expected size of the entire metacommunity is simply the sum of all of the average species’ \(n\). \[\begin{equation} \tag{14.3} J_M = \sum_{n=1}^{\infty} n \langle \phi_n^M \rangle = \theta \frac{x}{1-x} \end{equation}\] Thus the size of the metacommunity is an emergent property of the dynamics, rather than an external constraint. To my mind, it seems that the number of individuals in the metacommunity must result from responses of individuals to their external environment.
Volkov et al. went on to derive expressions for births, deaths, and average relative abundances in the local community. Given that each individual has an equal probability of dying and reproducing, and that replacements can also come from the metacommunity with a probability proportional to their abundance in the metacommunity, one can specify rules for populations in local communities of a fixed size. These are the probability of increase, \(b_{n,k}\), or decrease, \(d_{n,k}\), in a species, \(k\), of population size \(n\). \[\begin{align} b_{n,k} & = \left(1-m\right)\frac{n}{J_L}\frac{J_L-n}{J_L-1} + m\frac{\mu_k}{J_M}\left(1-\frac{n}{J_L}\right) \tag{14.4}\\ d_{n,k}&=(1-m)\frac{n}{J_L}\frac{J_L-n}{J_L-1} + m\left(1-\frac{\mu_k}{J_M}\right)\frac{n}{J_L} \tag{14.5} \end{align}\] These expressions are the sum of two joint probabilities, each of which is comprised of several independent events. These events are immigration, and birth and death of individuals of different species. Here we describe these probabilities. For a population of size \(n\) of species \(k\), we can indicate per capita, per death probabilities including
- \(m\), the probability that a replacement is immigrant from the metacommunity, and \(1-m\), the probability that the replacement is from the local community.
- \(n/J_L\), the probability that an individual selected randomly from the local community belongs to species \(k\), and \(1 - n/J_L\) or \((J-n)/(J_L)\), the probability that an individual selected randomly from the local community belongs to any species other than \(k\).
- \((J-n)/(J_L-1)\), the conditional probability that, given that an individual of species \(k\) has already been drawn from the population, an individual selected randomly from the local community belongs to any species other than to species \(k\).
- \(\mu_k/J_M\), the probability that an individual randomly selected from the metacommunity belongs to species \(k\), and \(1 - n/J_M\), the probability that an individual randomly selected from the metacommunity belongs to any species other than \(k\).
Each of these probabilities is the probability of some unspecified event — that event might be birth, death, or immigration.
Before we translate (14.4), (14.5) literally, we note that \(b\) and \(d\) each have two terms. The first term is for dynamics related to the local community, which happen with probability \(1-m\). The second is related to immigration from the metacommunity which occurs with probability \(m\). Consider also that if a death is replaced by a birth of the same species, or a birth is countered by a death of the same species, they cancel each other out, as if nothing ever happened. Therefore each term requires a probability related to species \(k\) and to non-\(k\).
Eq. (14.4), \(b_{n,k}\), is the probability that an individual will be added to the population of species \(k\). The first term is the joint probability that an addition to the population comes from within the local community (\(1-m\)) and the birth comes from species \(k\) (\(n/J_L\)) and there is a death of an individual of any other species (\((J_L-n)/(J_L-1)\)).90 The second term is the joint probability that the addition to the population comes from the metacommunity via immigration (\(m\)) and that the immigrant is of species \(k\) (\(\mu_k/J_M\)) and is not accompanied by a death of an individual of its species (\(n/J_L\)).
An individual may be subtracted from the population following similar logic. Eq. \(\ref{eq:d}\), \(d_{n.k}\), is the probability that a death will remove an individual from the population of species \(k\). The first term is the joint probability that the death occurs in species \(k\) (\(n/J_L\)) and the replacement comes from the local community (\(1-m\)) and is some species other than \(k\) (\((J_L-n)/(J_L-1)\)). The second term is the joint probability that the death occurs in species \(k\) (\(n/J_L\)), and that it is replaced by an immigrant (\(m\)) and the immigrant is any species in the metacommunity other than \(k\) (\(1-\mu_k/J_M\)).
14.7.2 Investigating neutral communities
Here we explore neutral communities using the untb package, which contains a variety of functions for teaching and research on neutral theory.
Pure drift
After loading the package and setting graphical parameters, let’s run a simulation of drift. Recall that drift results in the slow extinction of all but one species. We start with a local community with 20 species, each with 25 individuals91 The simulation then runs for 1000 generations (where 9/900 individuals die per generation). Note that display.untb() is great for pretty pictures, whereas untb() is better for more serious simulations.]
We keep in a matrix all 450 trees from each of the 1000
time steps so that we can investigate the properties of the
community. The output is a matrix where each element is an integer
whose value represents a species ID. Rows are time steps and we can
think of columns as spots on the ground occupied by trees. Thus a
particular spot of ground may be occupied by an individual of one
species for a long time, and suddenly switch identity, because it dies
and is replaced by an individual of another species. Thus the
community always has 450 individuals (columns), but the identities of
those 450 change through time, according to the rules laid out in
(14.4), (14.5). Each different species is represented by a different integer; here we show the identities of ten individuals (columns) for generations 901–3.
( a2 <- a[901:903, 1:10 ] )## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
## [1,] 6 2 20 20 20 10 10 6 15 15
## [2,] 6 2 20 20 20 10 10 6 15 15
## [3,] 6 2 20 20 20 10 10 6 15 15Thus, in generation 901, tree no. 1 is species 6 and in generation 902, tree no. 3 is species 20.
We can make pretty pictures of the communities at time steps 1, 100, and 2500, by having a single point for each tree, and coding species identity by shades of grey. We could use a nice color palette, hcl(), based on hue, chroma, and luminance, for instance hcl(a[i,]*30+50).
This function applies to the community, at each time step, the grey() function. Recall that species identity is an integer; we use that integer to characterize each species’ shade of grey.
Next we create the three graphs at three time points, with the appropriate data, colors, and titles.
layout(matrix(1:3, nr=1))
par(mar=c(1,1,3,1))
for(j in 1:3){
plot(c(1,20), c(1,25), type="n", axes=FALSE)
points(rep(1:20,25), rep(1:25,each=20), pch=19, cex=2, col=sppcolors[,j])
title(paste("Time = ", times[j], sep=""))
}
layout(matrix(1:9, nr=3, byrow=TRUE))
par(mar=c(1,1,3,1))
for(j in 1:3){
plot(c(1,20), c(1,25), type="n", axes=FALSE)
points(rep(1:20,25), rep(1:25,each=20), pch=19, cex=1.5, col=sppcolors[,j])
title(paste("Time = ", times[j], sep=""))
}
par(mar=c(5,4,1,1))
for(i in times){
plot(as.count(a[i,]),
ylim=c(1,max(as.count(a[2000,]))), xlim=c(0,20))
}
par(mar=c(6,4,1,3))
out <- lapply(times, function(i) preston(a[i,]) )
bins <- matrix(0, nrow=3, ncol=length(out[[3]]) )
for(i in 1:3) bins[i,1:length(out[[i]])] <- out[[i]]
bins## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9]
## [1,] 0 0 0 0 0 20 0 0 0
## [2,] 0 0 0 0 0 18 2 0 0
## [3,] 0 0 0 1 1 1 3 0 2
colnames(bins) <- names(preston(a[times[3],]))
for(i in 1:3){
par(las=2)
barplot(bins[i,], ylim=c(0,20), xlim=c(0,8), ylab="No. of Species", xlab="Abundance Category" )
}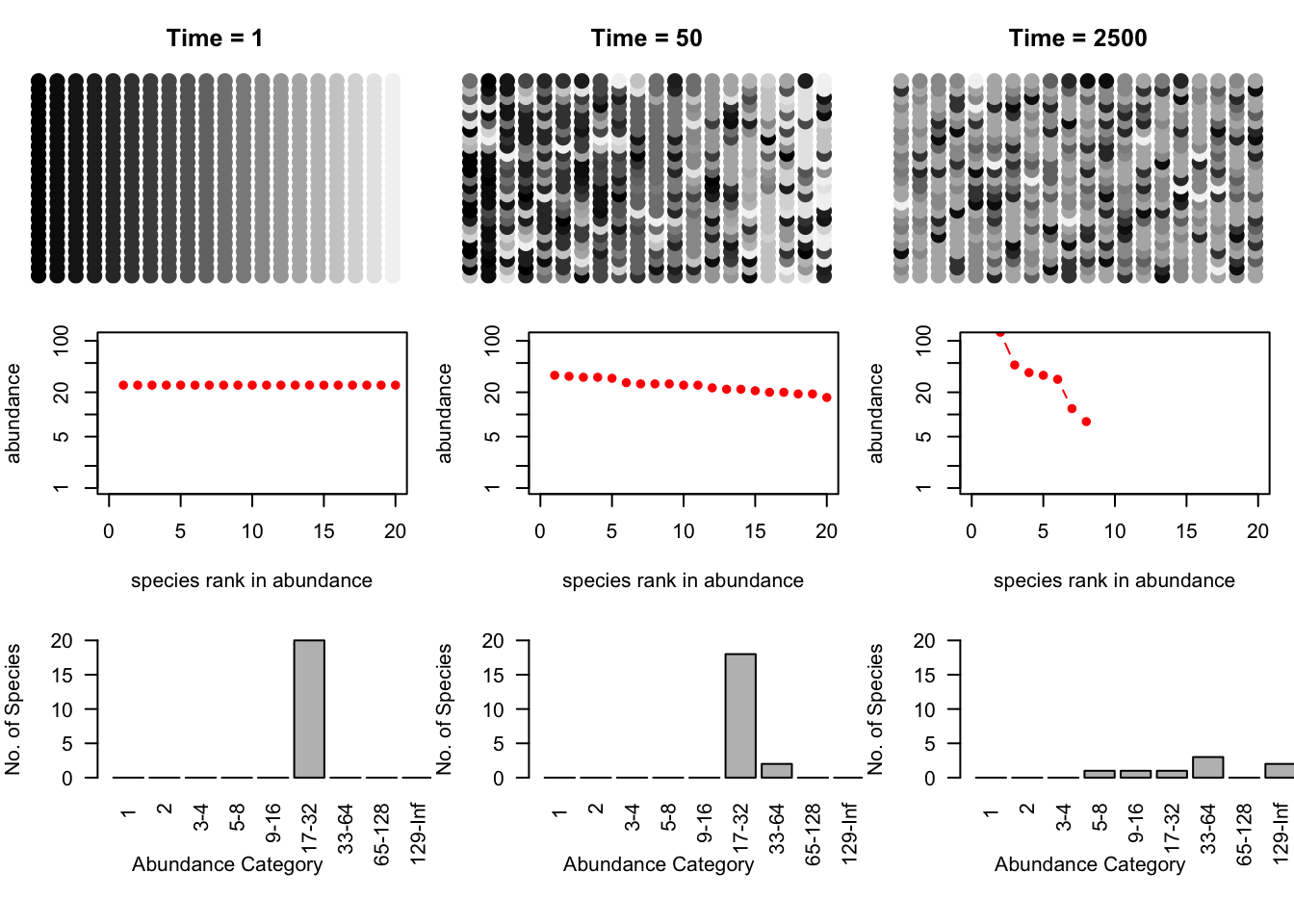
Figure 14.10: Three snapshots of one community, drifting through time. Shades of grey represent different species. The second and third rows are the rank-abundances and species -abundance distributions corresponding to the communities above. Drift results in the slow loss of diversity.
Bottom line: drift causes the slow loss of species from local communities (Fig. 14.10). What is not illustrated here is that without dispersal, drift will cause different species to become abundant in different places because the variation is random. In that way, drift maintains diversity at large scales, in the metacommunity. Last, low rates of dispersal among local communities maintains some diversity in local communities without changing the entire metacommunity into a single large local community. Thus dispersal limitiation, but not its absence, maintains diversity.
Next, let’s examine the dynamics through time. We will plot individual species trajectories (Fig. \(\ref{spptable}\)).
sppmat <- species.table(a)
matplot(1:times[3], sppmat[1:times[3],], type='l', ylab="Population Density")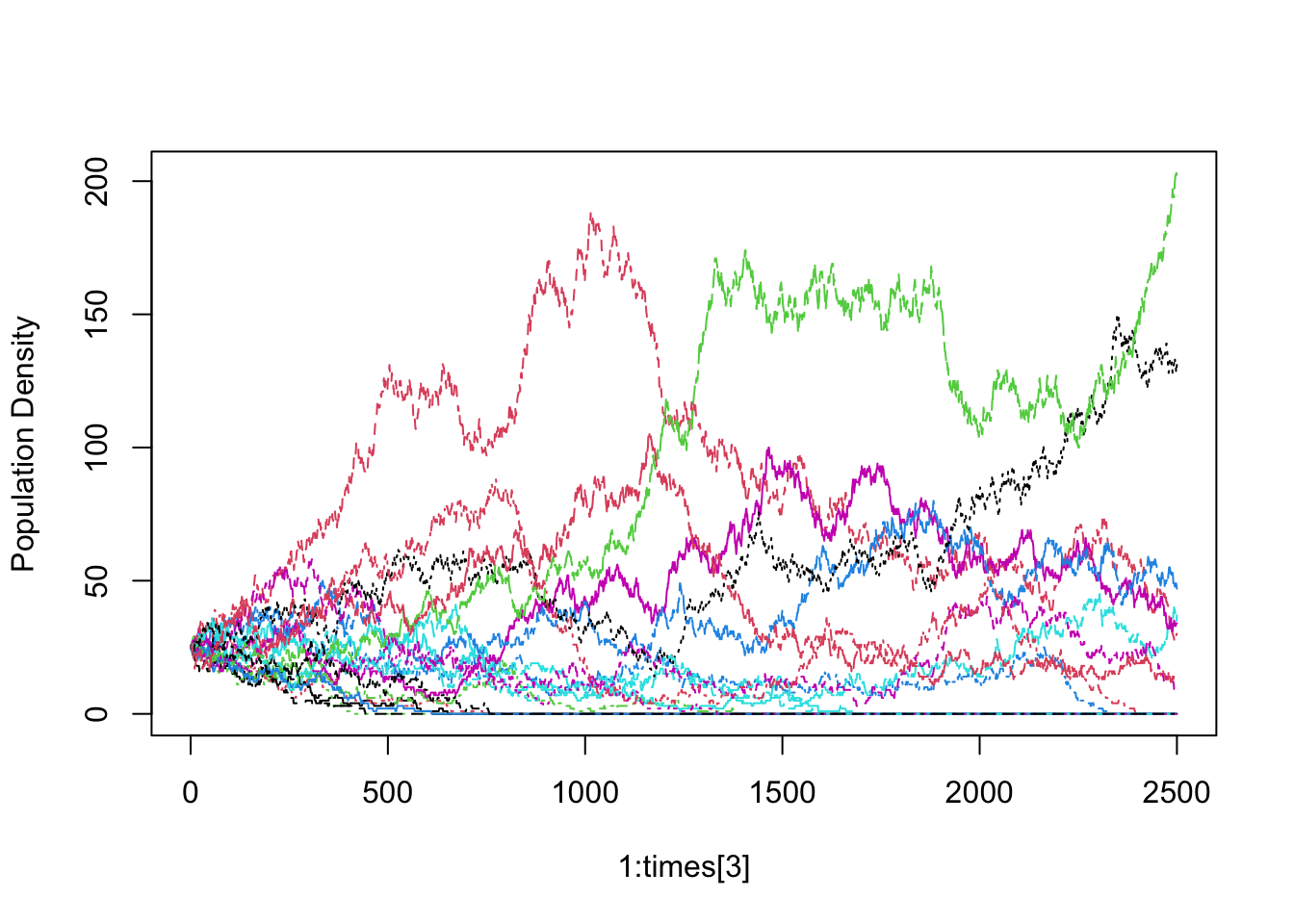
The trajectories all start at the same abundance, but they need not have. The trajectories would still have the same drifting quality.
For random walks in general, the observed variance and coefficient of variation (\(CV=\hat{\sigma}/\bar{x}\)) of a population will grow over time (Clark and McLachlan 2003). Here we calculate the average population \(CV\) of cumulative observations (note the convenient use of nested (s)apply functions). Let’s calculate the \(CV\)’s for every tenth time step.
cvtimes <- seq(2, 2500, by=10)
CV.within <- sapply(cvtimes, function(i) {# Use sapply with i as a row counter
## For each row i, use apply to caluculate the variance for each
## population from 1:i
cvs <- apply(sppmat[1:i,],2, function(x) sd(x)/mean(x) )
mean(cvs) # get the mean among populations (for each i).
} )
#popvar.among <- apply(sppmat, 1, var)Now plot the average \(CV\) through time. The average observed \(CV\) should increase (Fig. \(\ref{vartime}\)).
plot( cvtimes, CV.within, type='l' )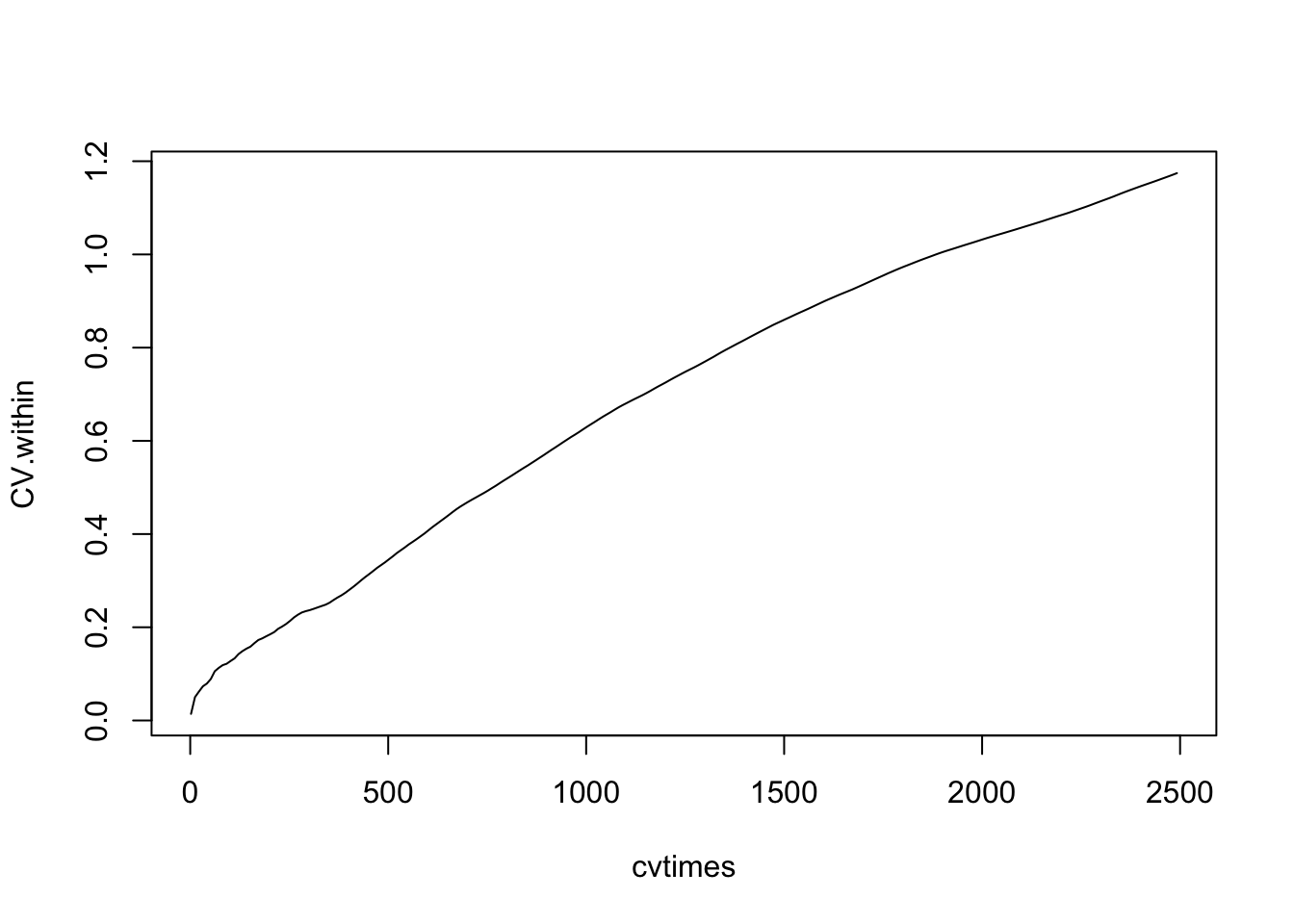 This shows us that the populations never approach an equilibrium, but wander aimlessly.
This shows us that the populations never approach an equilibrium, but wander aimlessly.Real data
Last, we examine the BCI data set (Oksanen et al. 2019). We load the data (data from 50 1,ha plots \(\times\) 225 species, from the vegan package), and sum species abundances to get each species total for the entire 50,h plot (Fig. ??).
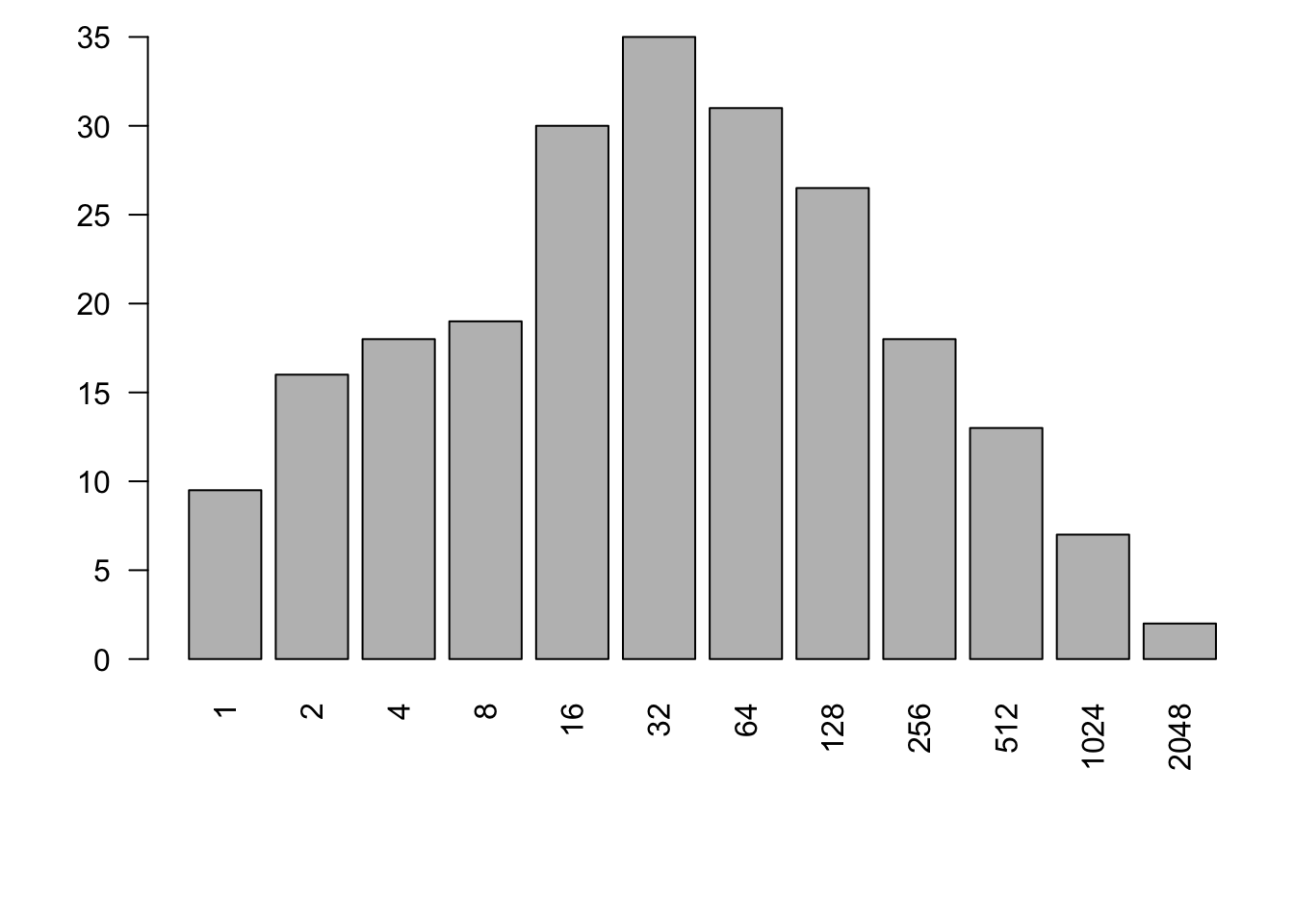 We would like to estimate \(\theta\) and \(m\) from these data, but that
requires specialized software for any data set with a realistic number
of individuals. Specialized software would provide maximum likelihood
estimates (in a reasonable amount of computing time) for \(m\) and
\(\theta\) for large communities (Alonso, Etienne, and McKane 2006; Hankin, R.K.S 2007; Jabot and Chave 2009). The BCI data have been used repeatedly, so we rely on estimates from the literature (\(\theta \approx 48\), \(m \approx 0.1\)) (Etienne 2007; Volkov et al. 2003). We use the approach of Volkov et al. (2003) to generate expected species abundances (Fig. ??).
We would like to estimate \(\theta\) and \(m\) from these data, but that
requires specialized software for any data set with a realistic number
of individuals. Specialized software would provide maximum likelihood
estimates (in a reasonable amount of computing time) for \(m\) and
\(\theta\) for large communities (Alonso, Etienne, and McKane 2006; Hankin, R.K.S 2007; Jabot and Chave 2009). The BCI data have been used repeatedly, so we rely on estimates from the literature (\(\theta \approx 48\), \(m \approx 0.1\)) (Etienne 2007; Volkov et al. 2003). We use the approach of Volkov et al. (2003) to generate expected species abundances (Fig. ??).
v1 <- volkov(sum(n), c(48, 0.1), bins=TRUE)
plot(preston(rep(1:225,n), n=12, original=TRUE))
points(xs, v1[1:12], type='b')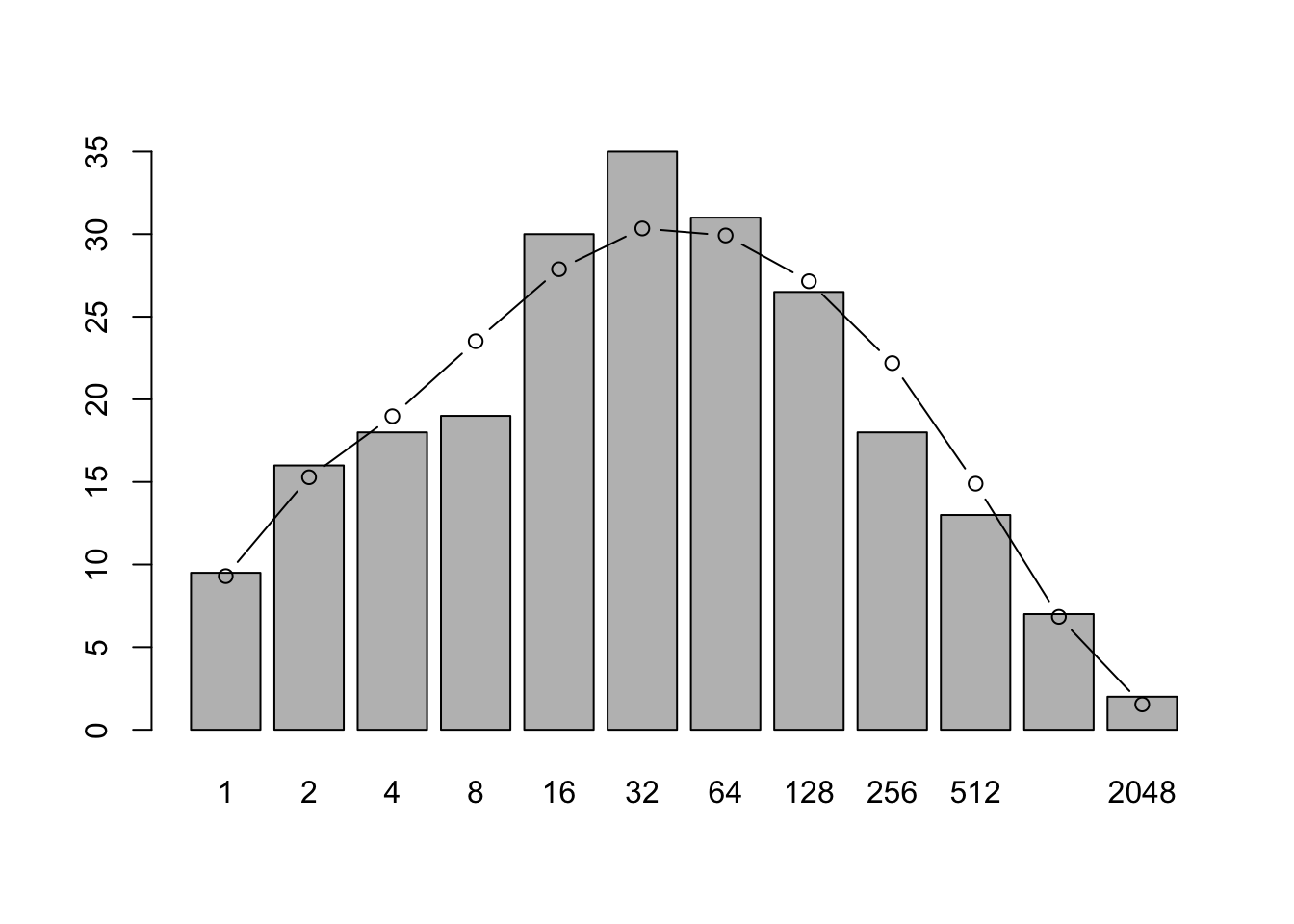 Jabot and Chave (2009) arrived at estimates that differed from previous estimates by orders of magnitude. Their novel approach estimated \(\theta\) and \(m\) were derived from both species abundance data and from phylogenetic data (\(\theta \approx 571\), \(m \approx 0.002\)). This is possible because neutral theory makes a rich array of predictions, based on both ecological and evolutionary processes. Their data were only a little bit different (due to a later census), but their analyses revealed radically different estimates, with a much greater diversity and larger metacommunity (greater \(\theta\)), and much lower immigration rates (smaller \(m\)).
Jabot and Chave (2009) arrived at estimates that differed from previous estimates by orders of magnitude. Their novel approach estimated \(\theta\) and \(m\) were derived from both species abundance data and from phylogenetic data (\(\theta \approx 571\), \(m \approx 0.002\)). This is possible because neutral theory makes a rich array of predictions, based on both ecological and evolutionary processes. Their data were only a little bit different (due to a later census), but their analyses revealed radically different estimates, with a much greater diversity and larger metacommunity (greater \(\theta\)), and much lower immigration rates (smaller \(m\)).
Here we derive expected species abundance distributions. The first is based solely on census data, and is similar to previous expections. However, when they also included phylogenetic data, they found very different expected species abundance distributions (Fig. 14.11).
# Census data only
v2 <- volkov(sum(n), c(48, 0.1), bins=TRUE)
# With phylogenetic data as well.
v4 <- volkov(sum(n), c(571, 0.002), bins=TRUE)
plot(preston(rep(1:225,n), n=12, original=TRUE))
xs <- plot(preston(rep(1:225,n), n=12, original=TRUE))
axis(1, at=xs, labels=FALSE)
points(xs, v2[1:12], type='b', lty=1, col=1)
points(xs, v4[1:12], type='b', lty=2, col=2)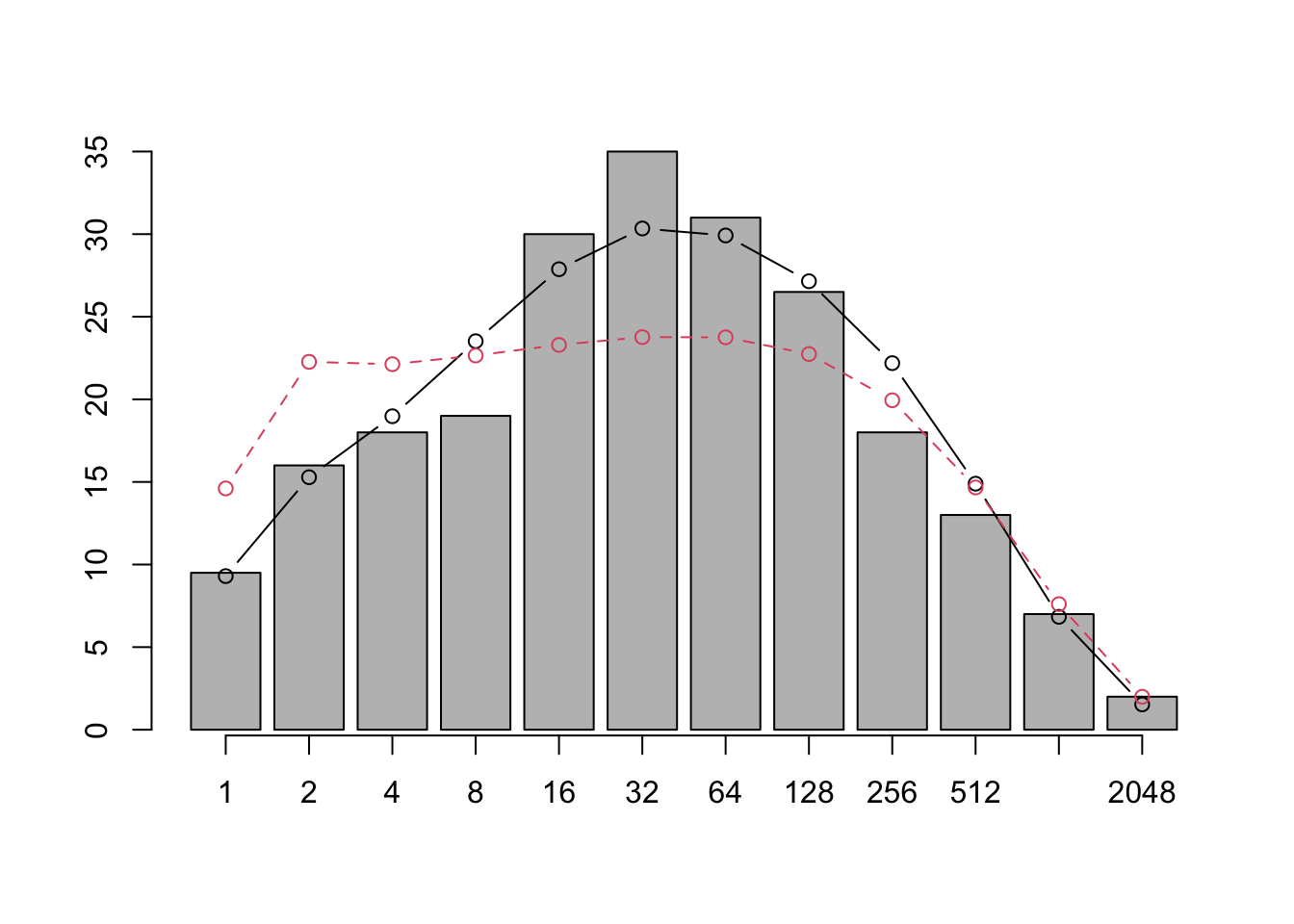
Figure 14.11: Jabot and Chave found that when they used only species abundances (as did previous investigators) their pattern was similar to previous findings (solid line). However, adding phylogenetic information led to very different expectations (dashed line).
Symmetry and the rare species advantage
An important aspect of neutral theory is the quantification of a symmetric rare species advantage. The symmetry hypothesis posits that all species have a symmetrical rare species advantage (Volkov et al. 2005, 2007). That is, all species increase when rare to the same degree (equal negative density dependence). In a strict sense, all individuals remain the same in that their birth and death probabilities change with population size in the same manner for all species. This obviously reduces the chance of random walks to extinction, but is nonetheless the same among all species. Estimation of the magnitude of the rare species advantage is interesting addition to stepwise increasing complexity.
To sum up: it is safe to say that neutral theory has already made our thinking about community structure and dynamics more sophisticated and subtle, by extending island biogeography to individuals. The theory is providing quantitative, pattern-generating models, that are analogous to null hypotheses. With the advent of specialized software, theory is now becoming more useful in our analysis of data (Hankin, R.K.S 2007; Munoz et al. 2018).
14.8 Species–area relations
The number of species we observe clearly depends on the number of individuals we sample, which in turn may depend on the size of the area in which we count individuals. For this reason alone, we may be interested in the relation between species and area. However, area is alos important because it is likely correlated with habitat heterogeneity, dispersal limitation, and even reproductive isolation. The study of species-area relations includes understanding how all these things fit together.
The relation between the number of species found in samples of different area has a long tradition (Arrhenius 1921; R. H. MacArthur 1972; Robert H. MacArthur and Wilson 1963; R. H. MacArthur and Wilson 1967; Preston 1960; Rosenzweig 1995), and is now an important part of the subdiscipline of macroecology (J. H. Brown 1995; J. Harte et al. 2008).
Most generally, the species–area relation (SAR) is simply an empirical pattern of the number of species found in patches of different size, plotted as a function of the sizes of the respective patches. These patches may be isolated from each other, as islands in the South Pacific (Robert H. MacArthur and Wilson 1963) (Fig. 14.12), or mountaintops covered in coniferous forest surrounded by a sea of desert (J. H. Brown and Davidson 1977), or calcareous grasslands in an agricultural landscape (Hambäack et al. 2007). On the other hand, these patches might be nested sets, where each larger patch contains all others (Crawley and Harral 2001).
Figure 14.12: The numbers of land and freshwater bird species on islands in Melanesia, Micronesia, and Polynesia. From MacArthur and Wilson (1963) An equilibrium theory of insular zoogeography. Evolution 17:373-387.
Quantitatively, the relation is most often proposed as a simple power law, \[\begin{equation} \tag{14.6} S = cA^z \end{equation}\] where \(S\) is the number of species in a patch of size \(A\), and \(c\) and \(z\) are fitted constants. This is most often plotted as a log–log relation, which makes it linear. \[\begin{equation} \tag{14.7} \log\left(S\right) = b + z \log(A) \end{equation}\] where \(b\) is the intercept (equal to \(\log c\)) and \(z\) is the slope. Other forms have been used, and sometimes better capture the relation (S. M. Scheiner 2003).
Here we simply draw some species area curves.
A <- 10^1:10; c <- 1.5; z <- 0.25
curve(c*x^z, 10, 10^10, n=500, ylab="No. of Species", xlab="Area (ha)")
curve(log(c,10) + z*x, 1, 10, ylab=quote(log[10]("No. of Species")),
xlab=quote(log[10]("Area (ha)")) )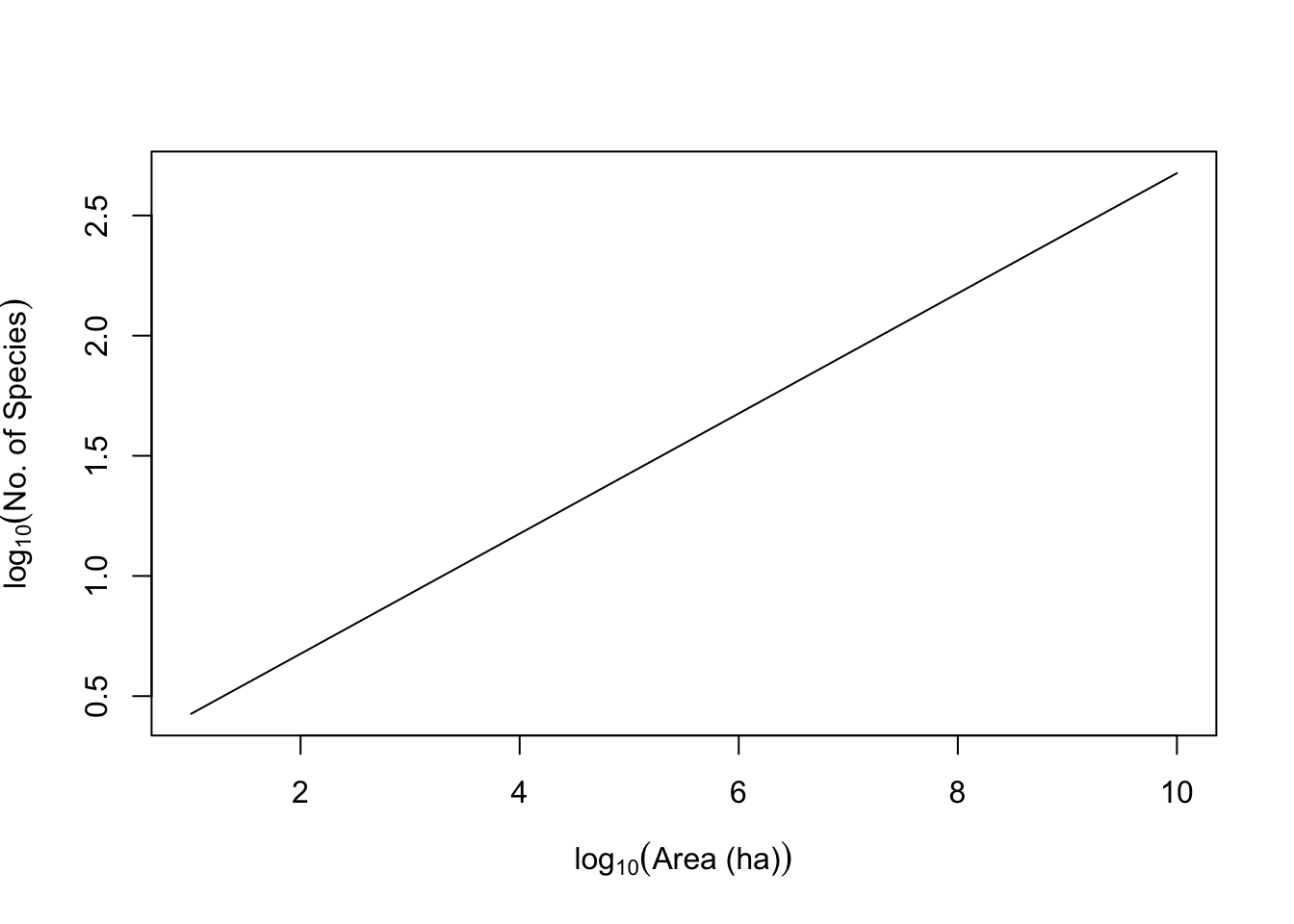
Here we fit a species–area curve to data, and examine the slope. We could fit a nonlinear power relation (\(y=cA^z\)); this would be appropriate, for instance, if the residual noise around the line were of the same magnitude for all patch areas. We could use reduced major axis regression, which is appropriate when there is equivalent uncertainty or error on both \(x\) and \(y\). Last (and most often), we could use a simple linear regression on the log-transformed data, which is appropriate when we know \(x\) to a high degree of accuracy, but measure \(y\) with some error, and the transformation causes the residual errors to be of similar magnitude at all areas. We start with the last (log-transformed). Here we plot the data, and fit a linear model to the common log-transformed data.
data(moths)
mod.nonlin <- nls(spp ~ a*area^z, start=list(a=1, z=.2),data=moths)
mod <- lm(log(spp,10) ~log(area,10), data=moths)
plot(log(spp,10) ~ log(area,10), moths)
abline(mod)
curve(log(coef(mod.nonlin)[1],10) + x*coef(mod.nonlin)[2],
0, 3, add=TRUE, lty=2)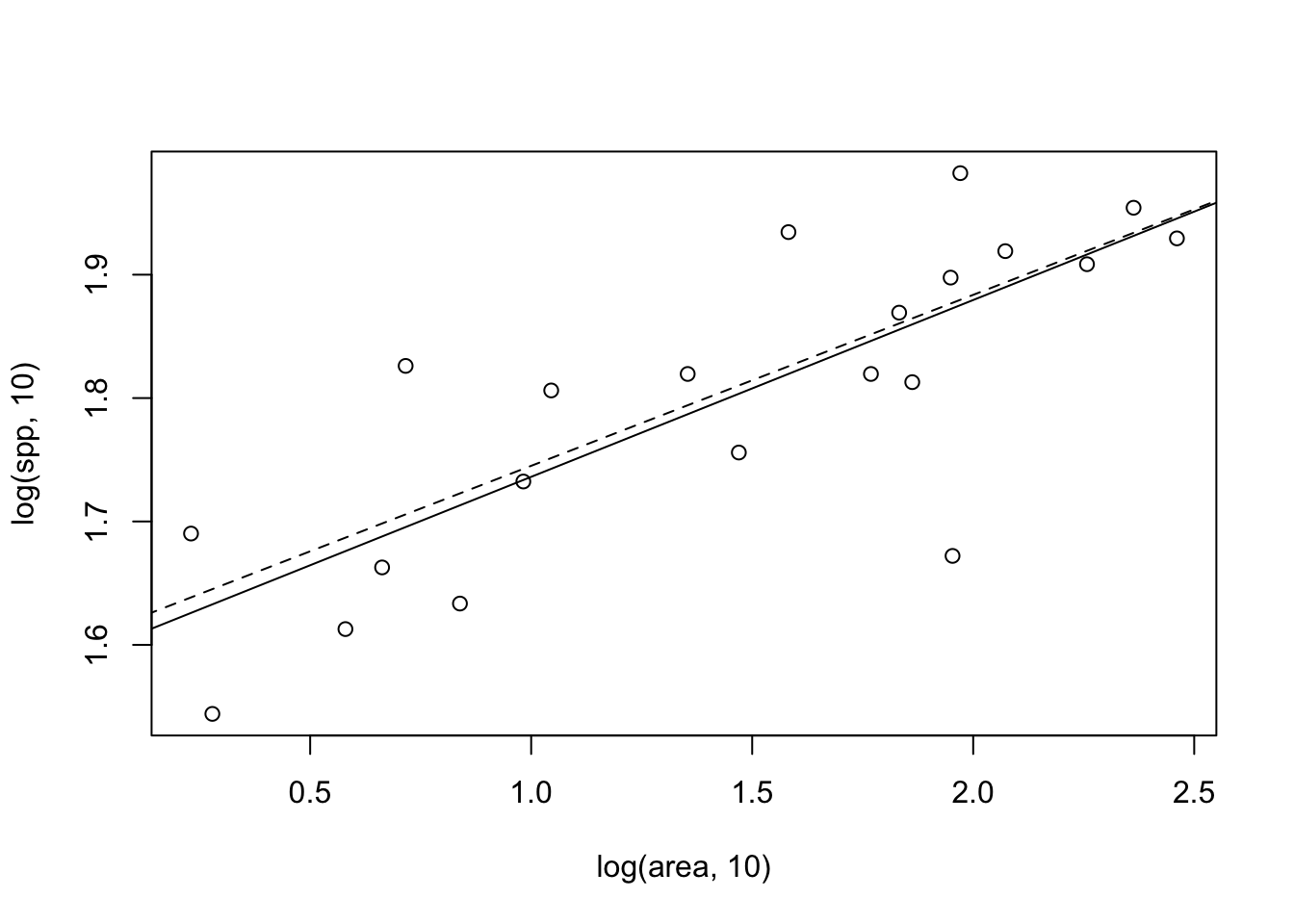
Figure 14.13: Two different fits to the moth species-area data: linear least squares on log-transformed data (solid line), and nonlinear least squares on the raw data (dashed line) for which the fit is plotted on the log-log scale.
Note that in Figure 14.13, the fits differ slightly between the two methods. Let’s compare the confidence intervals of the slopes — we certainly expect them to be similar, given the picture we just drew.
# linear fit to transformed data
confint(mod)## 2.5 % 97.5 %
## (Intercept) 1.50842866 1.677286
## log(area, 10) 0.09025952 0.196390
# nonlinear fit to raw data
confint(mod.nonlin)## 2.5% 97.5%
## a 31.61609496 50.1918074
## z 0.08491709 0.1957816We note that the estimates of the slopes are quite similar. In addition, \(\log a\) is also similar to the intercept of the linear model. Determining the better of the two methods (or others) is beyond the scope of this book, but be aware that methods can matter.
The major impetus for the species–area relation came from (i) Preston’s work on connections between the species–area relation and the log-normal species abundance distribution (Preston 1960, 1962), and (ii) MacArthur and Wilson’s theory of island biogeography (R. H. MacArthur and Wilson 1967).
Preston posited that, given the log-normal species abundance distributions (see above), then increasingly large samples should accumulate species at particular rates. Direct extensions of this work, linking neutral theory and maximum entropy theory to species abundances and species–area relations continued (J. Harte et al. 2008; Hubbell 2001).
14.8.1 Island biogeography
MacArthur and Wilson proposed a simple theory wherein the number of species on an oceanic island was a function of the immigration rate of new species, and extinction rate of existing species (Fig. 14.14). The number of species at any one time was a dynamic equilibrium, resulting from both slow inevitable extinction and slow continual arrival of replacements. Thus species composition on the island was predicted to change over time, that is, to undergo turnover. Our appreciation of the ecological and evolution processes that govern the number and variety of species on islands continues to grow (R. J. Whittaker et al. 2017).
Let us imagine immigration rate, \(y\), as a function of the number of species already on an island, \(x\) (Fig. 14.14). This relation will have a negative slope, because as the number of species rises, that chance that a new individual actually represents a new species will decline. The immigration rate will be highest when there are no species on the island, \(x=0\), and will fall to zero when every conceivable species is already there. In addition, the slope should be decelerating (concave up) because some species will be much more likely than others to immigrate. This means that the immigration rate drops steeply as the most likely immigrants arrive, and only the unlikely immigrants are missing. Immigrants may colonize quickly for two reasons. First, as Preston noted, some species are simply much more common than others. Second, some species are much better dispersers than others.
Now let us imagine extinction rate, \(y\), as a function of the number of species, \(x\) (Fig. 14.14). This relation will have a positive slope, such that the probability of extinction increases with the number of species. This is predicted to have an accelerating slope (concave-up), for essentially the same sorts of reasons governing the shape of the immigration curve: Some species are less common than others, and therefore more likely to become extinct due to demographic and environmental stochasticity, and second, some species will have lower fitness for any number of reasons. As the number of species accumulates, the more likely it will become that these extinction-prone species (rare and/or lower fitness) will be present, and therefore able to become extinct.
The rate of change of the number of species on the island, \(\Delta S\), will be the difference between immimigration, \(I\), and extinction, \(E\), or \[\begin{equation} \tag{14.8} \Delta S = I - E. \end{equation}\] When \(\Delta S = 0\), we have an equilibrium. If we knew the quantitative form of immigration and extinction, we could solve for the equilibrium. That equilibrium would be the point on the \(x\) axis, \(S\), where the two rates cross (Fig. 14.14).
In MacArthur and Wilson’s theory of island biogeography, these rates could be driven by the sizes of the islands, where
- larger islands had lower extinction rates because of larger average population sizes, and
- larger islands had higher colonization rates because they were larger targets for dispersing species.
The distance between an island and sources of propagules was also predicted to influence these rates, where
- islands closer to mainlands had higher colonization rates of new species because more propagules would be more likely to arrive there, and
- the effect of area would be more important for islands far from mainlands than for islands close to mainlands.
Like much good theory, these were simple ideas, but had profound effects on the way ecologists thought about communities. Now these ideas, of dispersal mediated coexistence and landscape structure, continue to influence community ecologists.
Drawing immigration and extinction curves
It would be fun to derive a model of immigration and extinction rates from first principles (Robert H. MacArthur and Wilson 1963), but here we can illustrate these relations with some simple phenomenological graphs. The code that follows recreates Fig. 14.14, and also estimates \(S\).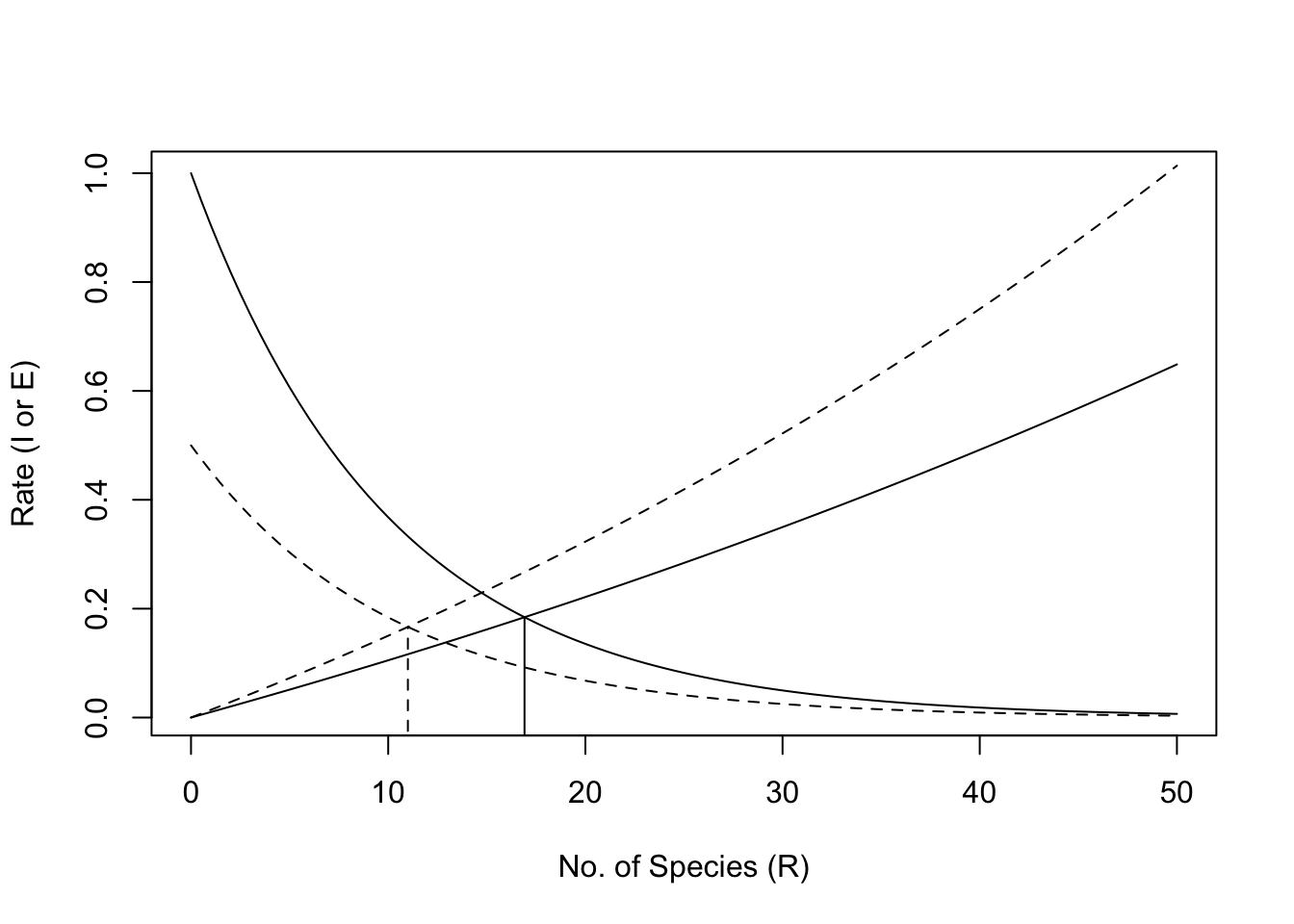
Figure 14.14: Immigration and extinction curves for the theory of island biogeography. The declining curves represent immigration rates as functions of the number of species present on an island. The increasing curves represent extinction rates, also as functions of island richness. See text for discussion of the heights of these curves, i.e., controls on these rates. Here the dashed lines represent an island that is shrinking in size.
We will assume that immigration rate, \(I\), can be represented as a simple negative exponential function \(\exp (I_0 - iS)\), where \(I_0\) is the rate of immigration to an empty island, and \(-i\) is the per species negative effect on immigration rate.
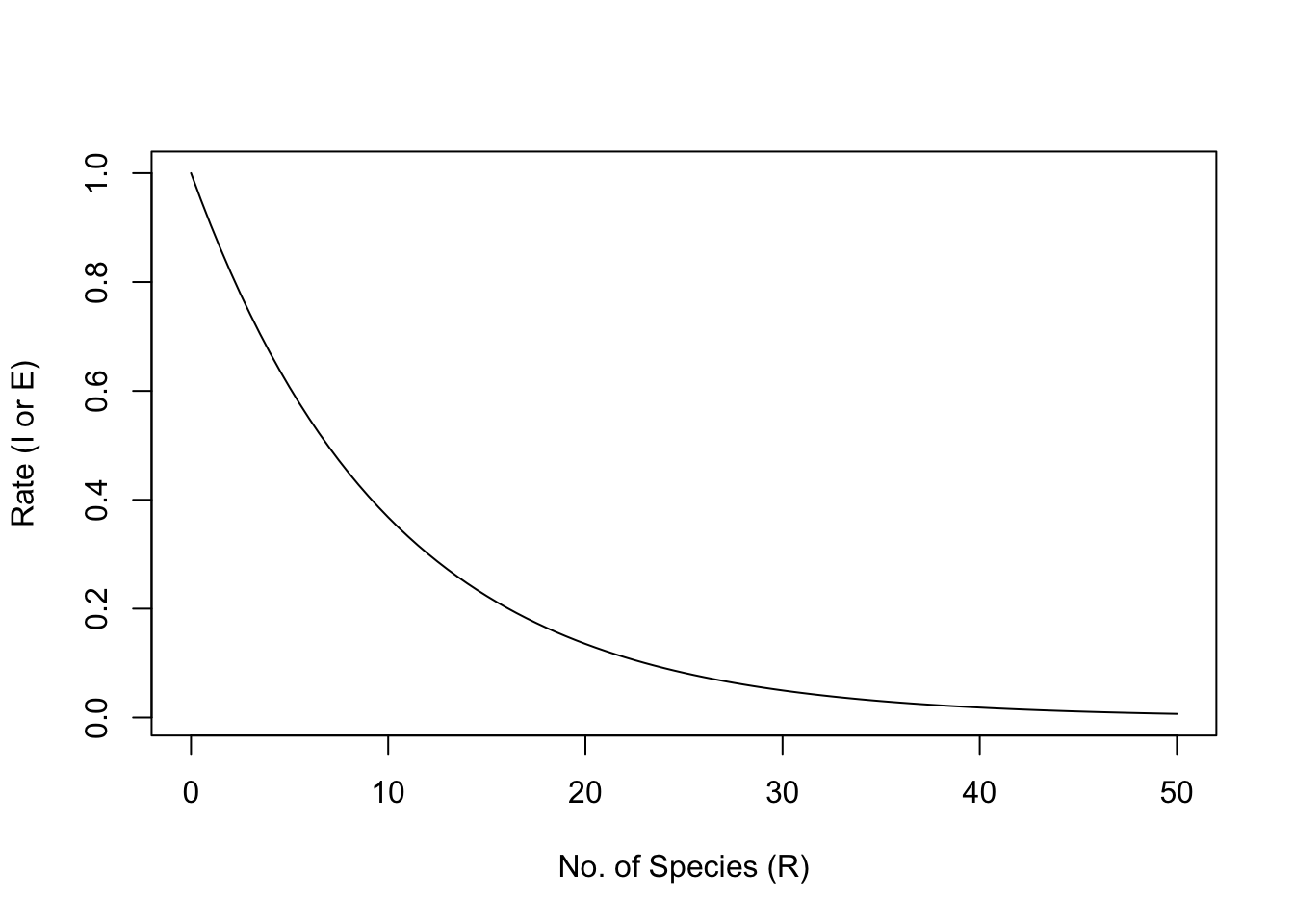 Note that extinction rate, \(E\), must be zero if there are no species present. Imagine that extinction rate is a function of density and that average density declines as the number of species increases, or \(\bar{N} = 1/S\).92
Note that extinction rate, \(E\), must be zero if there are no species present. Imagine that extinction rate is a function of density and that average density declines as the number of species increases, or \(\bar{N} = 1/S\).92
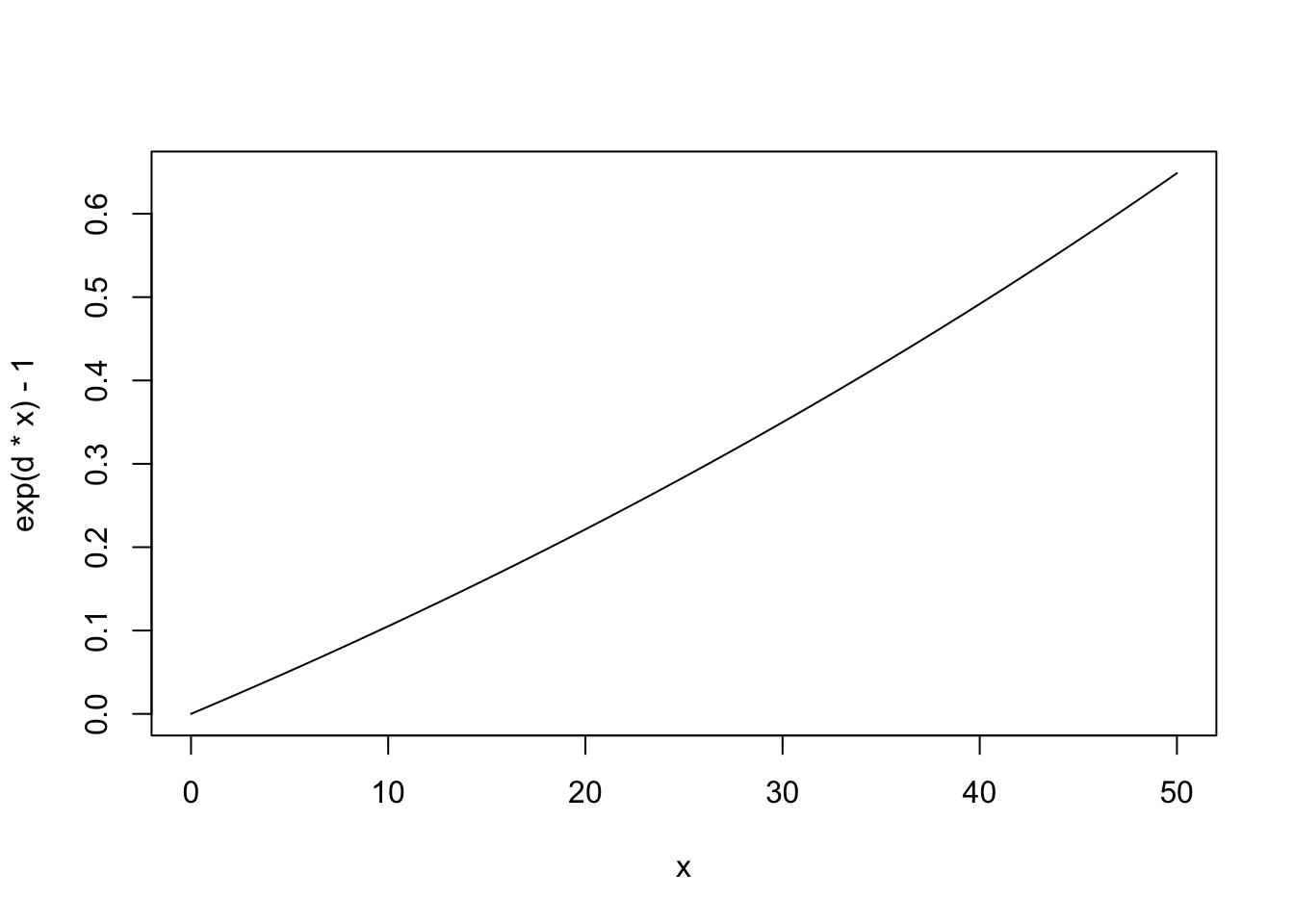
# use add=TRUE to add the line to a previous graphWe subtract 1 merely to make sure that \(E=0\) when \(R=0\).
The number of species, \(R\), will result from \(\Delta S = 0= I-E\), the point at which the lines cross. \[\begin{gather} I = e^{I_0 - bS}\\ E = e^{dS}-1 \\ \delta S = 0 = I-E \end{gather}\] Here we find this empirically by creating a function of \(S\) to minimize — we will minimize \((I-E)^2\); squaring the difference gives the quantity the convenient property that the minimum will be approached from either positive or negative values.
We feed this into an optimizer for one-parameter functions, and specify that we know the optimum will be achieved somewhere in the interval between 1 and 50.
## [1] 16.91321The output tells us that the minimum was achieved when \(S \approx 16.9\).
Now imagine that rising sea level causes island area to shrink. What is this predicted to do? It could
- reduce the base immigration rate because the island is a smaller target,
- increase extinction rate because of reduced densities.
Let us represent reduced immigration rate by reducing \(I_0\).
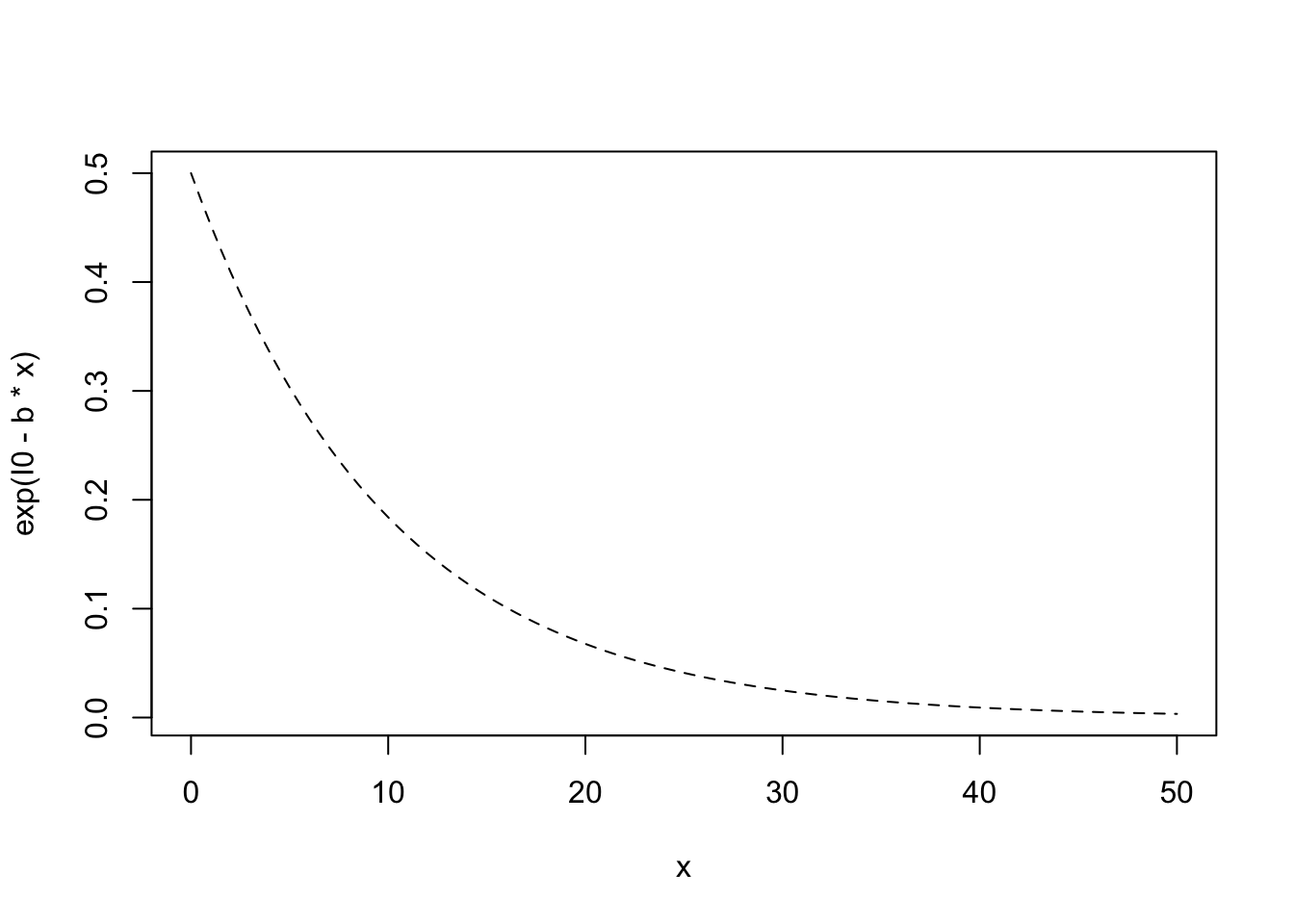
# use add=TRUE to add to a previous plotNext we increase extinction rate by increasing the per species rate.
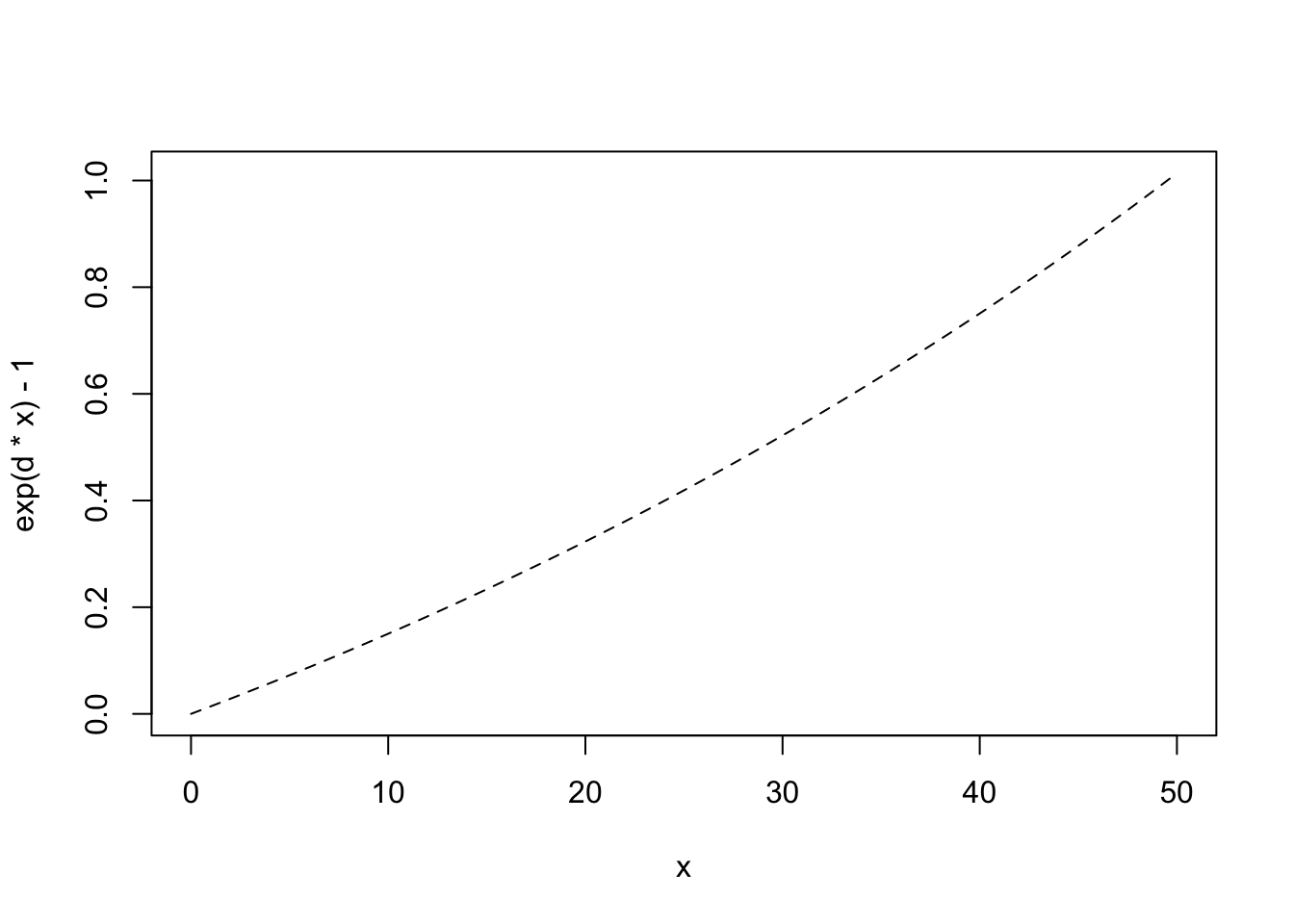
If we note where the rates cross, we find that the number of predicted species has declined. With these new immigration and extinciton rates the predicted number of species is
## [1] 10.99834or 11 species, roughly a 35% decline (\((17-11)/17 = 0.35\)).
The beauty of this theory is that it focuses our attention on landscape level processes, often outside the spatial and temporal limits of our sampling regimes. It specifies that any factor which helps determine the immigration rate or extinction rate, including island area or proximity to a source of propagules, is predicted to alter the equilibrium number of species at any point in time. We should further emphasize that the identity of species should change over time, that is, undergo turnover, because new species arrive and old species become extinct. The rate of turnover, however, is likely to be slow, because the species that are most likely to immigrate and least likely to become extinct will be the same species from year to year.
14.9 Diversity Partitioning
We frequently refer to biodiversity (i.e., richness, Simpson’s, and Shannon-Wiener diversity) at different spatial scales as \(\alpha\), \(\beta\), and \(\gamma\) diversity.
- Alpha diversity, \(\alpha\), is the diversity of a point location or of a single sample.
- Beta diversity, \(\beta\), is the diversity due to multiple localities. As we saw above, \(\beta\) diversity is also used to describe differences in species composition among sites.
- Gamma diversity, \(\gamma\), is the diversity of a region, or at least the diversity of all the species in a set of samples collected over a large area (with large extent relatve to a single sample).
Diversity across spatial scales can be further be partitioned in one of two ways, either using additive ormultiplicative partitioning.
Additive partitioning (Crist and Veech 2006; Crist et al. 2003; Lande 1996) is represented as \[\begin{equation} \tag{14.9} \bar{\alpha} + \beta = \gamma \end{equation}\] where \(\bar{\alpha}\) is the average diversity of samples, \(\gamma\) is typically the diversity of the pooled samples, and \(\beta\) is found by difference (\(\beta = \gamma - \bar{\alpha}\)). We can think of \(\beta\) as the average number of species not found in a sample, but which we know to be in the region. Additive partitioning allows direct comparison of average richness among samples at any hierarchical level of organization because all three measures of diversity (\(\alpha\), \(\beta\), and \(\gamma\)) are expressed in the same units. This makes it analogous to partitioning variance in ANOVA. This is not the case for multiplicative partitioning diversity.
R. H. Whittaker (1960) proposed a multiplicative partitioning of diversity,
\[\begin{equation}
\tag{14.10}
\bar{\alpha}\beta = \gamma
\end{equation}\]
where \(\beta\) is a conversion factor that describes the relative change in species composition among samples. Sometimes this type of \(\beta\) diversity is thought of as the number of different community types in a set of samples. However, one must use this interpretation with great caution, as either meaning of \(\beta\) diversity depends completely on the sizes or extent of the samples used for \(\alpha\) diversity.
Figure 14.15: Hierarchical sampling of moth species richness in forest patches in Indiana and Ohio, USA. \(\alpha\)-diversity is the diversity of a single site (richness indicated by numbers). \(\gamma\)-diversity is the total number of species found in any of the samples (here \(\gamma=230\) spp.). Additive \(\beta\)-diversity is the difference, \(\gamma - \bar{\alpha}\), or the average number of species not observed in a single sample. Diversity partitioning can be done at two levels, sites within ecoregions and ecoregions within the geographic region (see example in text for details).
Let us examine the limits of \(\beta\) diversity in extremely small and extremely large samples. Imagine that our sample units each contain, on average, one individual (and therefore one species) and we have 10\(^6\) samples. If richness is our measure of diversity, then \(\bar{\alpha}=1\). Now imagine that in all of our samples we find a total of 100 species, or \(\gamma=100\). Our additive and multiplicative partitions would then be \(\beta_{A}=99\), and \(\beta_{M}=100\), respectively. If the size of the sample unit increases, each sample will include more and more individuals and therefore more of the diversity, and by definition, \(\beta\) will decline. If each sample gets large enough, then each sample will capture more and more of the species until a sample gets so large that it includes all of the species (i.e., \(\bar{\alpha} \to \gamma\)). At this point, \(\beta_A \to 0\) and \(\beta_M \to 1\).
a <- seq(1,100, by=.1)
g <- max(a)
bA <- g-a
bM <- g/a
matplot(a, cbind(bA, bM), type='l', xlab=quote(bar(italic(alpha))), ylab=quote(italic(beta)), col=1)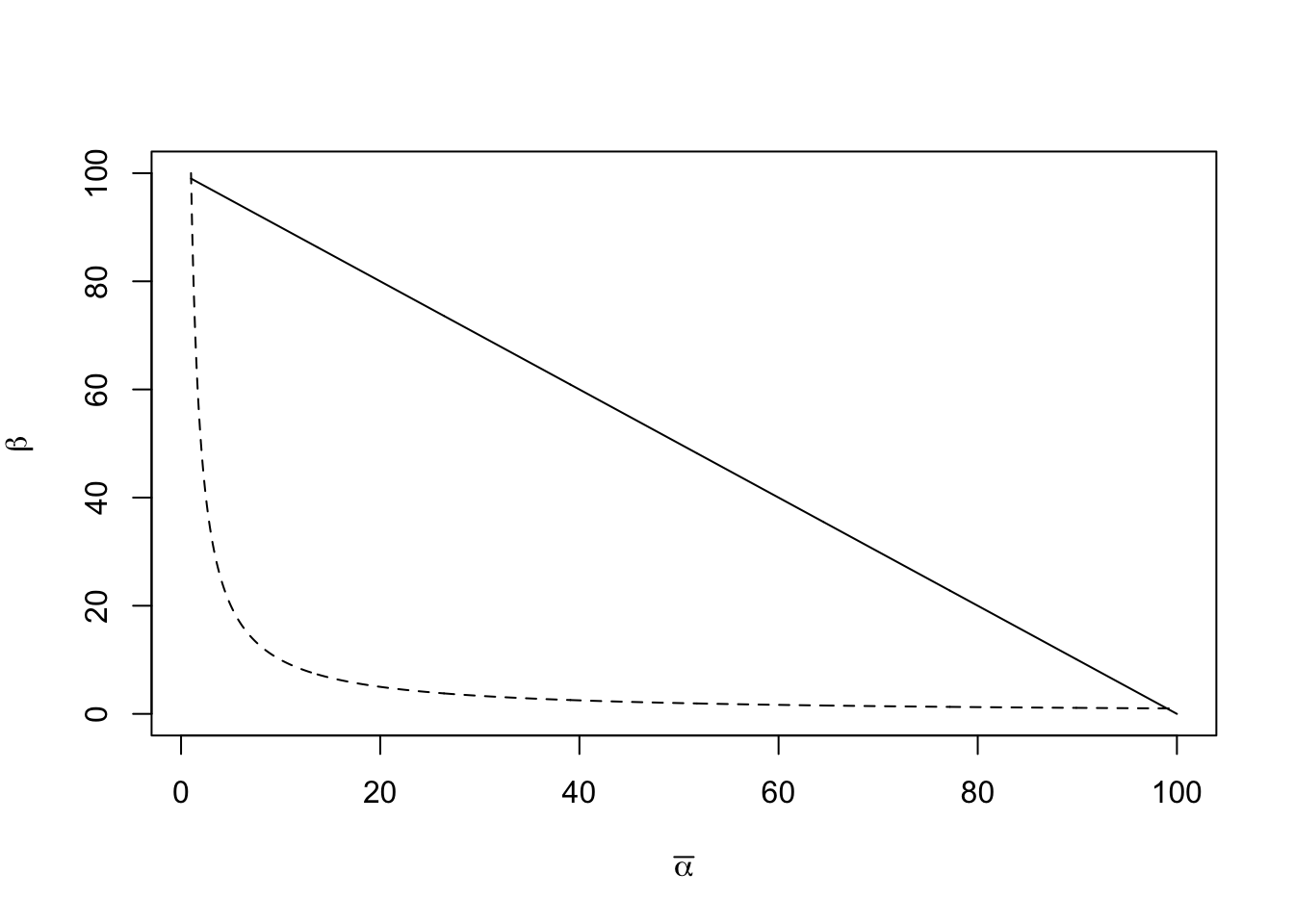
Figure 14.16: Relations of \(\beta_A\) (with additive partitioning) and \(\beta_M\) (with multiplicative partitioning) to \(\bar{\alpha}\), for a fixed \(\gamma=500\) species. In our example, we defined diversityas species richness, so the units of \(\beta_A\) and \(\alpha\) are number of species per sample, and \(\bar{\alpha}\) is the mean number of species in a sample. In contrast, in a multiplicative partition, \(\beta\) is the number of communities.
Note that \(\beta_A\) and \(\beta_M\) do not change at the same rates (Fig. \(\ref{fig:beta}\)). When we increase sample size so that each sample includes an average of two species (\(\bar{\alpha} = 2\)), then \(\beta_A = 98\) and \(\beta_M =50\). If each sample were big enough to have on average 50 species (\(\bar{\alpha} = 50\)), then \(\beta_A = 50\) and \(\beta_M =2\).
Multiplicative \(\beta_M\) is sometimes thought of as the number of independent “communities” in a set of samples. This would make sense if our sampling regime were designed to capture representative parts of different communities. For example, if we sampled an elevational gradient, or a productivity gradient, and our smallest sample was sufficiently large so as to be representative of that point along the gradient93 then \(\beta_M\) could provide a measure of the relative turnover in composition or “number of different communities.” However, we know that, all else being equal, composition is also predicted to vary randomly across the landscape. Therefore, if each sample is small, and not really representative of a community, then the small size of the samples will inflate \(\beta_M\) and change the interpretation.
As an example, consider the BCI data, which consists of 50 contiguous 1,ha plots. First, we find \(\gamma\) (all species in the data set, or the number of columns), and \(\bar{\alpha}\) (mean species number per 1,ha plot).
(gamma <- dim(BCI)[2])## [1] 225
(alpha.bar <- mean( specnumber(BCI) ))## [1] 90.78Next we find additive \(\beta\)-diversity and multiplicative \(\beta\)-diversity.
(beta.A <- gamma - alpha.bar)## [1] 134.22
(beta.M <- gamma/alpha.bar)## [1] 2.478519Now we interpret them. These plots are located in a relatively uniform tropical rainforest. Therefore, they each are samples drawn from a single community type. However, the samples are small. Therefore, each 1 ha plot (\(10^4\) m\(^2\) in size) misses more species than it finds, on average (\(\beta_A > \bar{\alpha}\)). In addition, \(\beta_M=2.48\), indicating a great deal of turnover in species composition. We could mistakenly interpret this as indicating something like \(\sim 2.5\) independent community types in our samples. Here, however, we have a single community type — additive partitioning is a little simpler and transparent in its interpretation.
For other meanings of \(\beta\)-diversity, linked to neutral theory, see (Morlon et al. 2008).
14.9.1 Partitioning species–area relations
You may already be wondering if there is a link between island biogeography and \(\beta\)-diversity. After all, as we move from island to island, and as we move from small islands to large islands, we typically encounter additional species, and that is what we mean by \(\beta\)-diversity. Sure enough, there are connections (Crist and Veech 2006), and the older edition of this primer walks you through them.
Let us consider a study of moth diversity (Fig. 14.15) by Keith Summerville and Thomas Crist (Summerville and Crist 2003, 2004). The subset of their data presented here consists of woody plant feeding moths collected in southwest Ohio, USA. Thousands of individuals were trapped in 21 forest patches, distributed in two adjacent ecoregions (12 sites - North Central Tillplain [NCT], and 9 sites - Western Allegheny Plateau [WAP], Fig. 14.15). This data set includes a total of 230 species, with 179 species present in the NCT ecoregion and 173 species present in the WAP ecoregion. From these subtotals, we can already see that each ecoregion had most of the combined total species (\(\gamma\)).
We will partition richness at three spatial scales: sites within ecoregions (\(\bar{\alpha}_1\)), ecoregions (\(\bar{\alpha}_2\)), and overall (\(\gamma\)). This will result in two \(\beta\)-diversities: \(\beta_1\) among sites within each ecoregion, and \(\beta_2\) between ecoregions. The relations among these are straightforward. \[\begin{gather} \tag{14.11} \bar{\alpha}_2 = \bar{\alpha}_1 + \beta_1\\ \gamma = \bar{\alpha}_2 + \beta_2 \\ \gamma = \bar{\alpha}_1 + \beta_1 + \beta_2 \end{gather}\]
To do this in R, we merely implement the above equations using the data in Fig. 14.15. First, we get the average site richness, \(\bar{\alpha}_1\). Because we have different numbers of individuals from different site, and richness depends strongly on the number of individuals in our sample, we may want to weight the sites by the number of individuals. However, I will make the perhaps questionable argument for the moment that because trapping effort was similar at all sites, we will not adjust for numbers of individuals. We will assume that different numbers of individuals reflect different population sizes, and let number of individuals be one of the local determinants of richness.
a1 <- mean(moths[['spp']])Next we calculate average richness richness for the ecoregions. Because we had 12 sites in NCT, and only nine sites in WAP for what might be argued are landscape constraints, we will use the weighted average richness, adjusted for the number of sites.94 We also create an object for \(\gamma=230\).
Next, we get the remaining quantities of interest, and show that the partition is consistent.
b1 <- a2-a1
b2 <- g-a2
abg <- c(a1=a1, b1=b1, a2=a2, b2=b2, g=g)
abg## a1 b1 a2 b2 g
## 65.42857 111.00000 176.42857 53.57143 230.00000
a1 + b1 + b2 == g## [1] TRUE
Figure 14.17: Hierarchical partitioning of moth species richness in forest patches.
The partitioning reveals that \(\beta_1\) is the largest fraction of overall \(\gamma\)-richness (Fig. 14.17). This indicates that in spite of the large distance between sampling areas located in different ecoregions, and the different soil types and associated flora, most of the variation occurs among sites within regions. If there had been a greater difference in moth community composition among ecoregions, then \(\beta_2\)-richness would have made up a greater proportion of the total.
These calculations show us how simple this additive partition can be, although more complicated analyses are certainly possible. It can be very important to weight appropriately the various measures of diversity (e.g., the number of individuals in each sample, or number of samples per hierarchical level). The number of individuals in particular has a tremendous influence on richness, but has less influence on Simpson’s diversity partitioning. The freely available PARTITION software will perform this additive partitioning (with sample sizes weights) and perform statistical tests (https://ecology.wp.txstate.edu/diversity-partitioning/).
Connecting to the species–area curve
The total number of moth species in all of the patches is, as before, \(\gamma\). The average richness of these patches is \(\bar{\alpha}\), and also note that part of what determines that average is the area of the patch. That is, when a species is missing from a patch, part of the reason might be that the patch is smaller than it could be. We will therefore partition \(\beta\) into yet one more category: species missing due to patch size, \(\beta_{area}\). This new quantity is the average difference between \(\bar{\alpha}\) and the diversity predicted for the largest patch (Fig. 14.18). In general then, \[\begin{equation} \tag{14.12} \beta = \beta_{area} + \beta_{replace} \end{equation}\] where \(\beta_{replace}\) is the average number of species missing that are not explained by patch size.
In the context of these data (Fig. 14.18), we now realize that \(\beta_1 = \beta_{area} + \beta_{ecoregion}\), so the full partition becomes \[\begin{equation} \tag{14.13} \gamma = \bar{\alpha}_1 + \beta_{area} + \beta_{ecoregion} + \beta_{geogr.region} \end{equation}\] where \(\beta_{replace} = \beta_{ecoregion} + \beta_{geogr.region}\). Note that earlier in the chapter, we did not explore the effect of area. In that case, \(\beta_{ecoregion}\) included both the effect of area and the effect of ecoregion; here we have further partitioned this variation into variation due to patch size, as well as variation due to ecoregion. This reduces the amount of unexplained variation among sites within each ecoregion.
Let’s calculate those differences now. We will use quantities we calculated above for \(\bar{\alpha}_1\), \(\bar{\alpha}_2\), \(\gamma\), and a nonlinear species–area model from above. We can start to create a graph similar to Fig. 14.18. We’ll start with fitting again a model we used above.
Now to plot data and draw a fitted line.
plot(spp ~ area, data=moths, ylim=c(30,230), #log='y',
xlab="Area (ha)", ylab="No. of Species (R)")
curve(coef(mod.nonlin)[1] * x^coef(mod.nonlin)[2],
0, max(moths[['area']]), add=TRUE, lty=2, lwd=2)
#text(150, 200,
# bquote(italic("R") == .(round(coef(mod.nonlin)[1],1)) *
# italic("A")^.(round(coef(mod.nonlin)[2],2)) )
# )
abline(h=g, lty=3)
text(275, g, quote(gamma), adj=c(.5,1.5), cex=1.5)Next we need to find the predicted richness for the maximum area. We use our statistical model to find that.
## [1] 88.6185We can now find \(\beta_{area}\), \(\beta_{eco}\) and \(\beta_{geo}\).
b.area <- MaxR - a1
b.eco <- a2-(b.area+a1)
b.geo <- g - a2Now we have partitioned \(\gamma\) a little bit more finely with a beastiary of \(\beta\)’s, where
- \(\bar{\alpha}_1\) is the average site richness.
- \(\beta_{area}\) is the average number of species not observed, due to different patch sizes.
- \(\beta_{eco}\) is the average number of species not observed at a site, is not missing due to patch size, but is in the ecoregion.
- \(\beta_{geo}\) is the average number of species not found in the samples from different ecoregions.
Finally, we add lines to our graph to show the partitions.
Now we have further quantified how forest fragment area explains moth species richness. Such understanding of the spatial distribution of biodiversity provides a way to better quantify patterns governed by both dispersal and habitat preference, and allows us to better describe and manage biodiversity in human-dominated landscapes.
Figure 14.18: Combining species–area relations with additive diversity partitioning. Forest fragment area explains relatively little of the diversity which accumulates in isolated patches distributed in space. However, it is likely that area associated with the collection of samples (i.e., the distances among fragments) contributes to \(\beta_{eco}\) and \(\beta_{geo}\).
14.10 In fine
We have examined communities as multivariate entities which we can describe and compare in a variety of ways.
- Composition includes all species (multivariate data), whereas species diversity is a univariate description of the variety of species present.
- There are many ways to quantify species diversity, and they tend to be correlated. The simplest of these is richness (the number of species present), whereas other statistics take species’ relative abundances into account.
- Species abundance distributions and rank abundance distributions are analogous to probability distributions, and provide more thorough ways to describe the patterns of abundance and variety in communities. These all illustrate a basic law of community ecology: most species are rare. Null models of community structure and processes make predictions about the shape of these distributions.
- Ecological neutral theory provides a dynamical model, not unlike a null model, which allows quantitative predictions relating demographic, immigration, and speciation rates, species abundance distributions, and patterns of variation in space and time.
- Another law of community ecology is that the number of species increases with sample area and appears to be influenced by immigration and extinction rates.
- We can partition diversity at different spatial scales to understand the structure of communities in landscapes.